[범용 인공 지능의 미래]AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION

On 25 Jan 2024, Stanford University, Microsoft Research, the University of California, Los Angeles and the University of Washington Co-published a surveying paper called: AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION
Abstract:
They try to draw the future of the Multi-modal AI systems. They present a new concept ‘Agent AI’, a promising avenue toward Artificial General Intelligence (AGI). (범용 인공 지능을 향한 유망한 길입니다.)
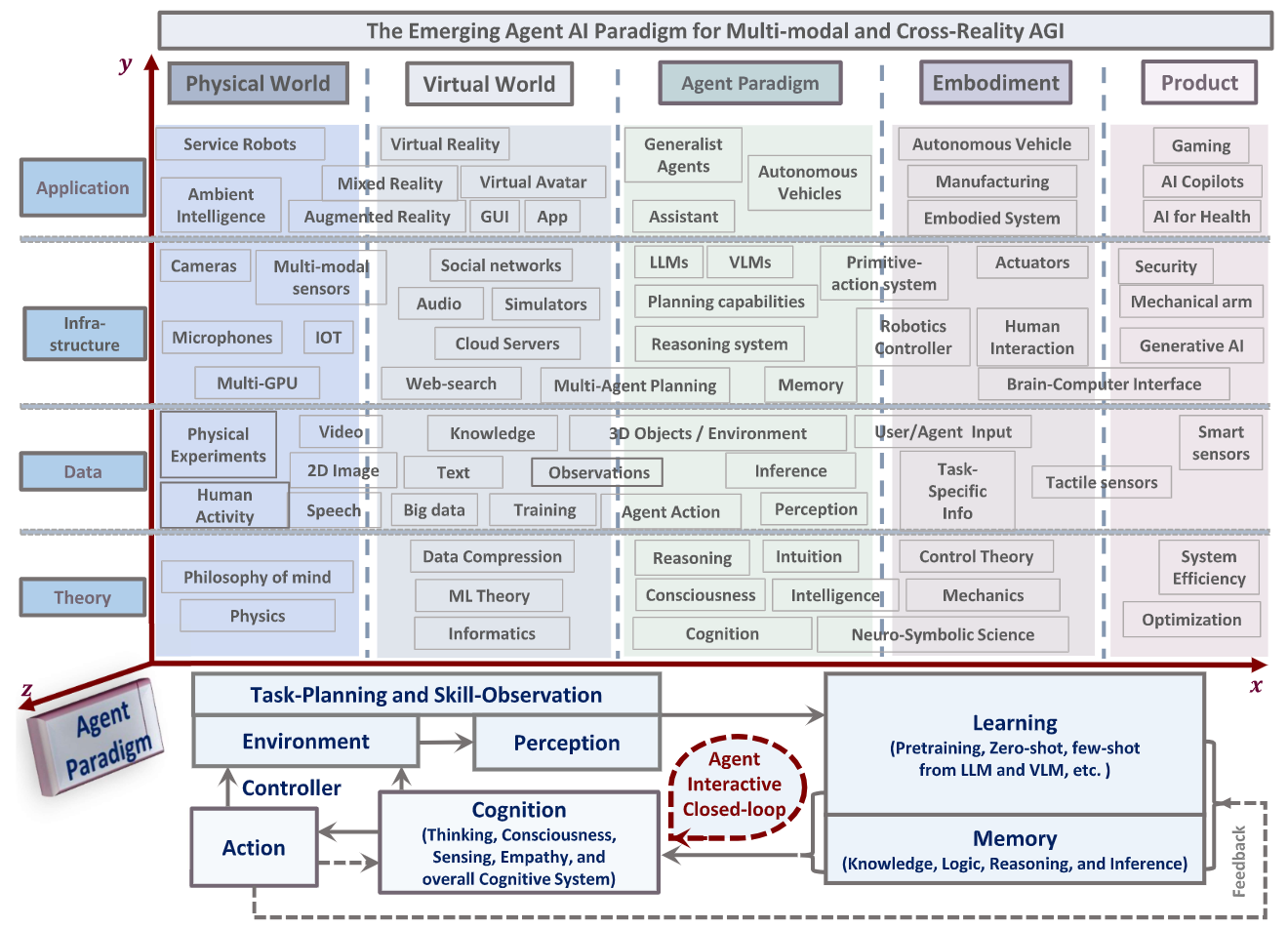
Agent AI system that can perceive and act in many different domains and applications, possibly serving as a route towards AGI using an agent paradigm(표준 양식]). — Figure 1
How to use ubiquitous(어디에나 있는) multi-modal AI systems?
Agents within physical and virtual environments(현실 및 가상 환경의 에이전트) like the Jarvis in Iron Man(아이언맨의 자비스처럼).
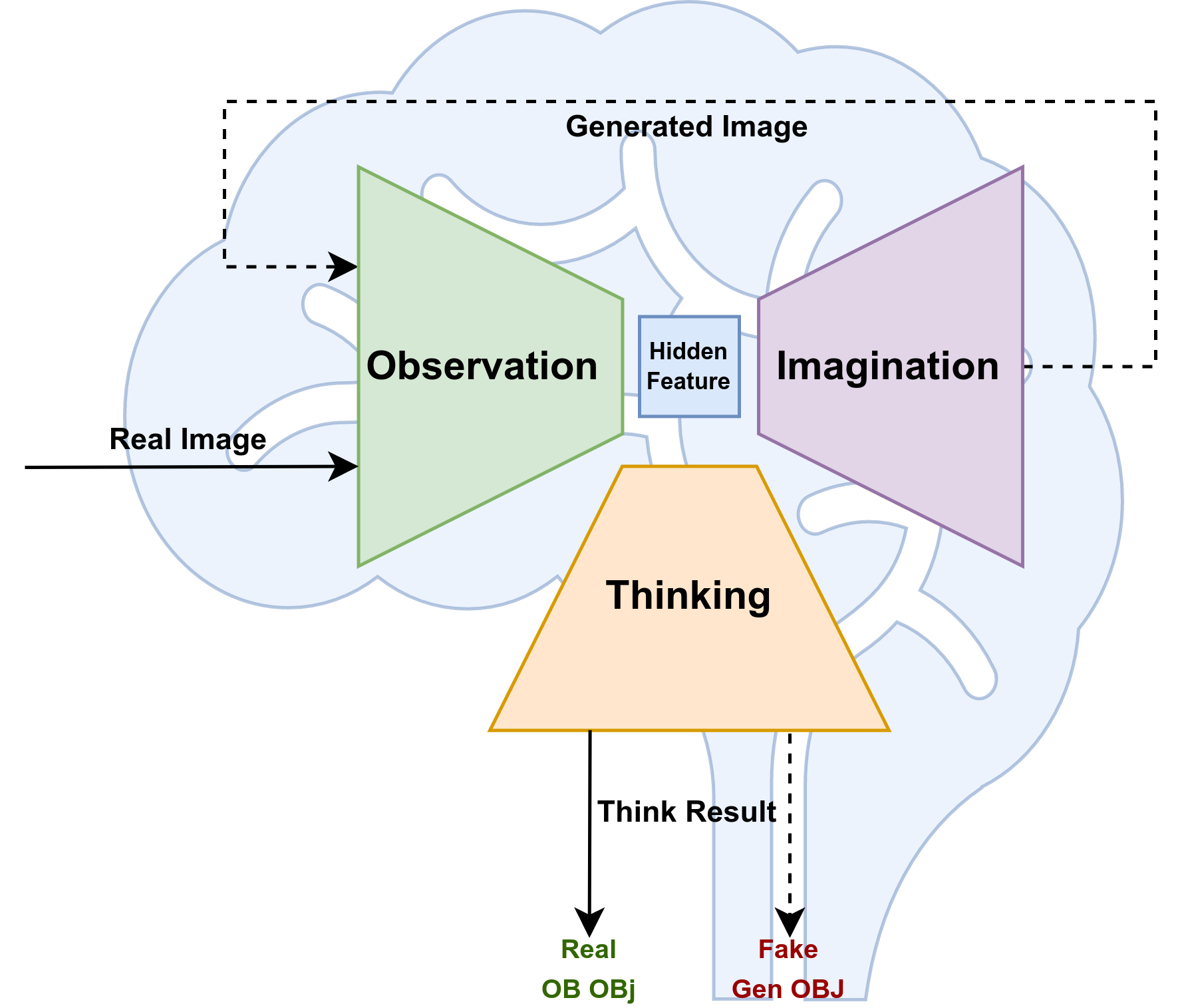
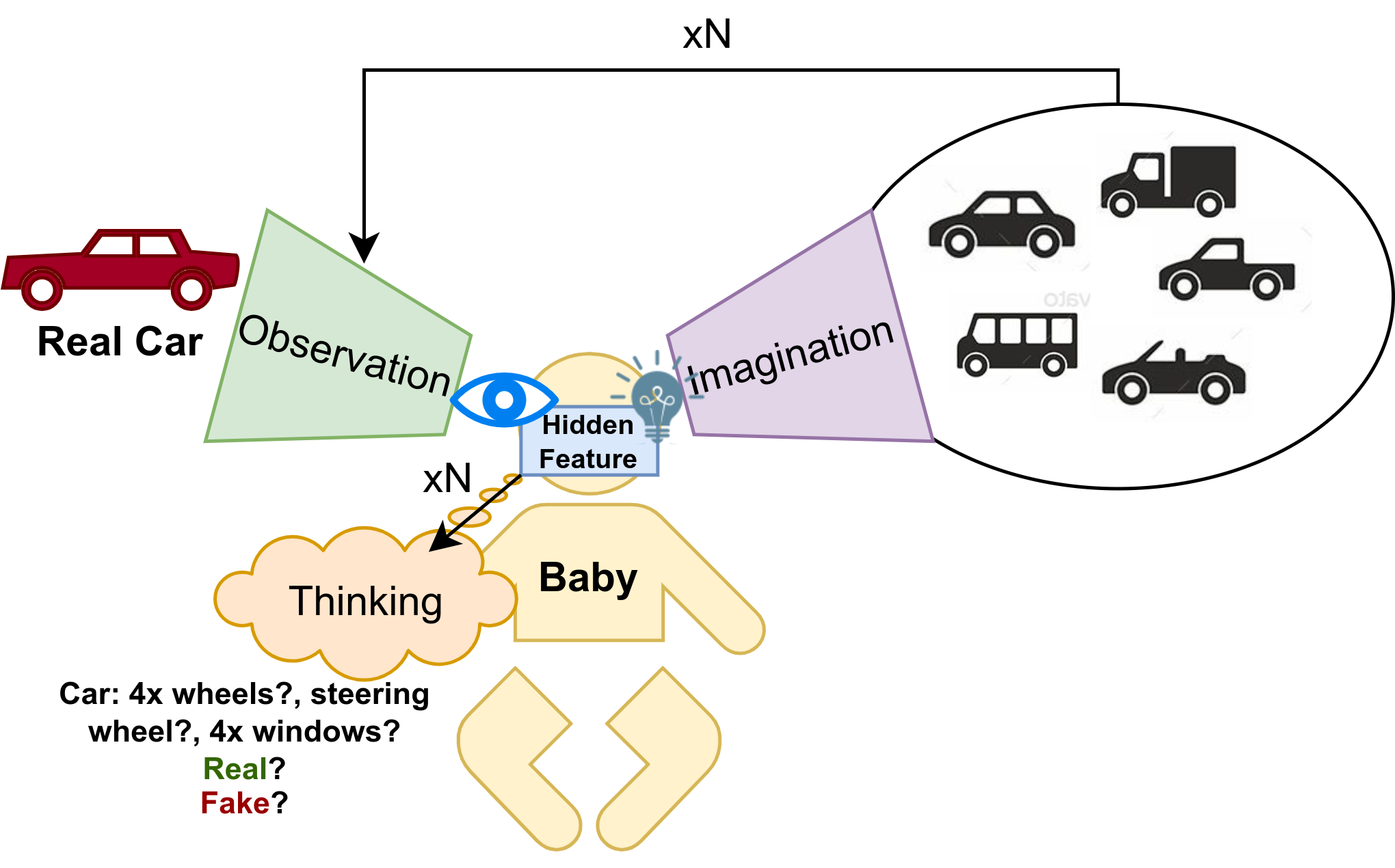
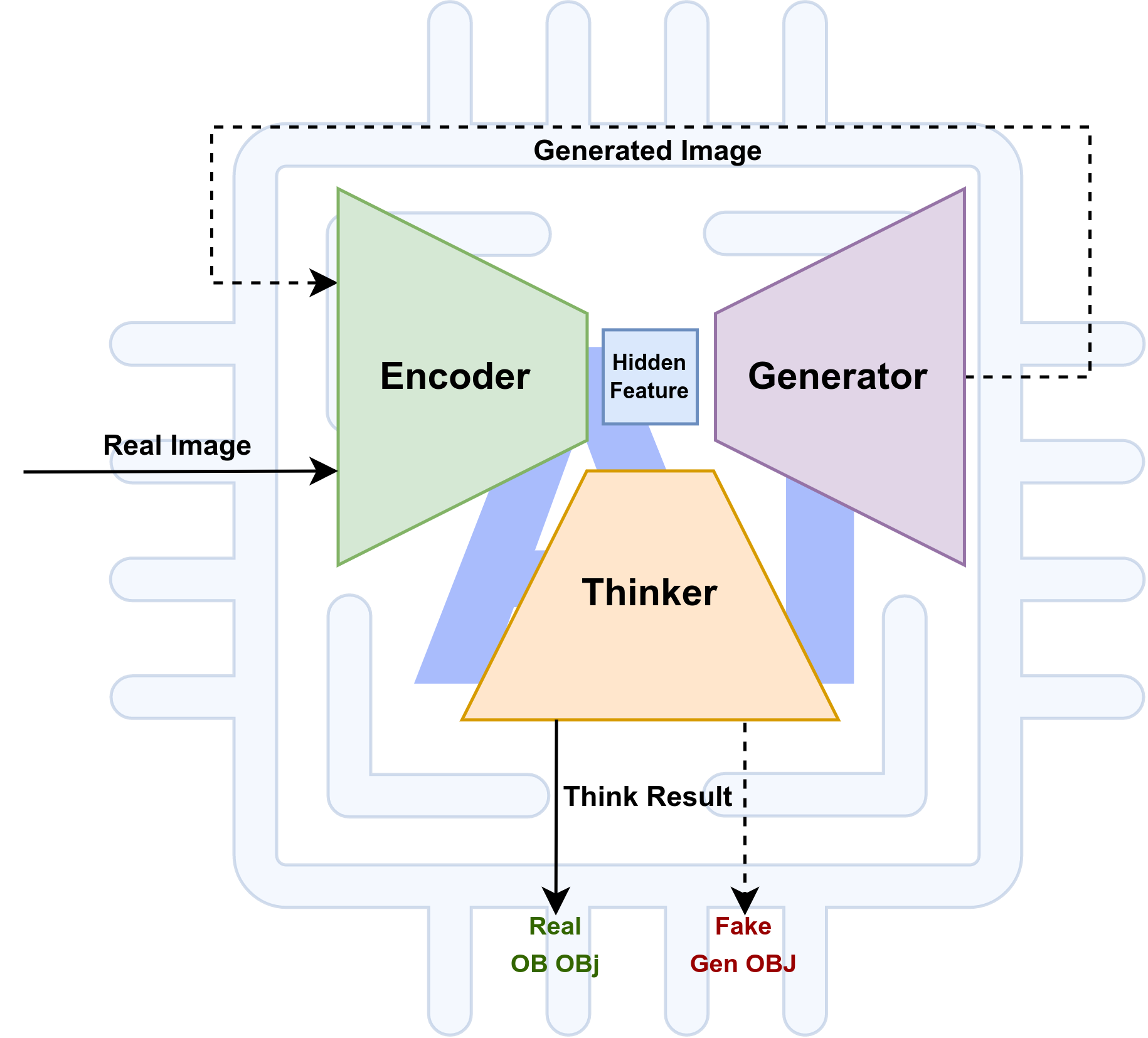
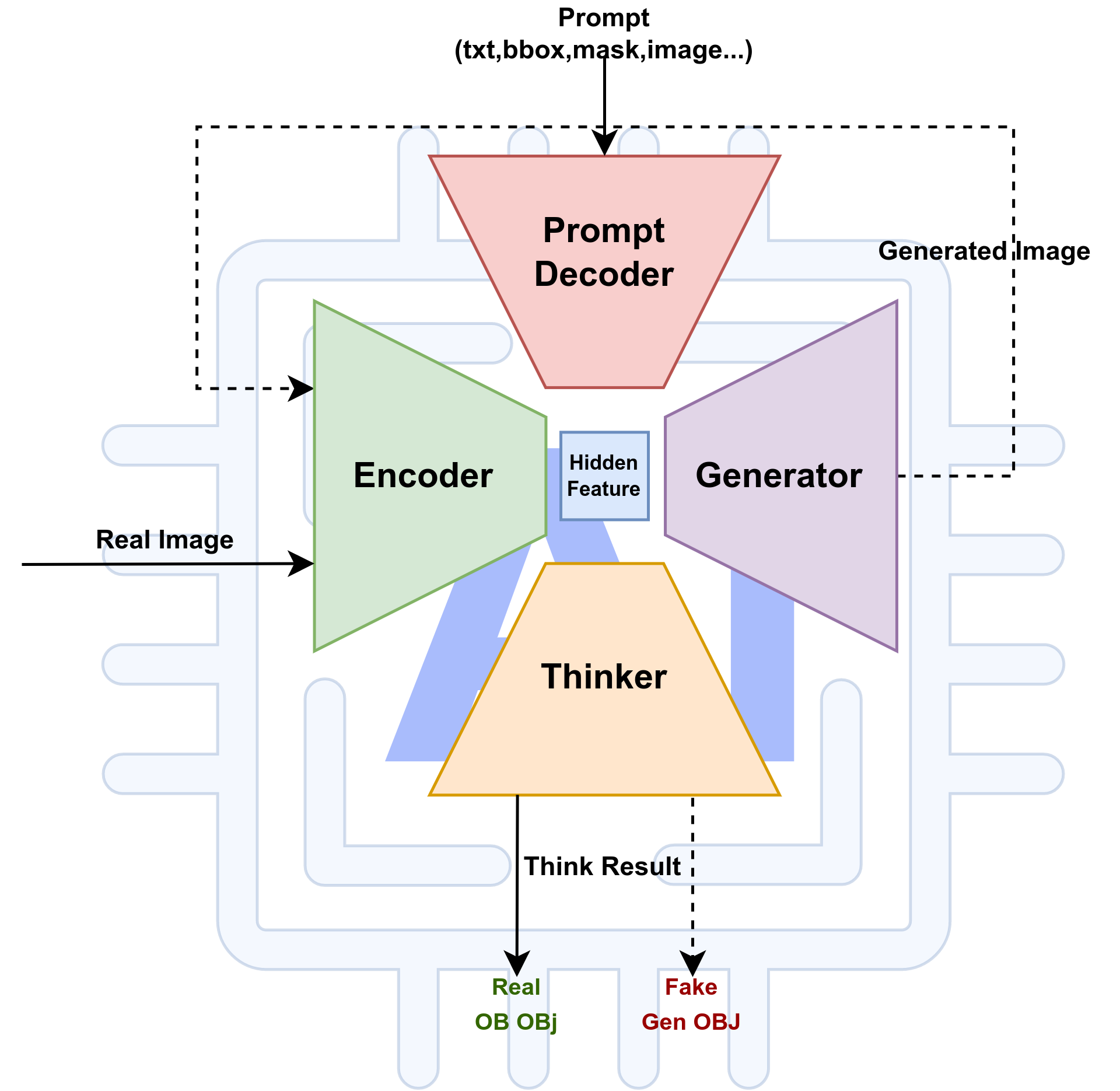
Overview of an Agent AI system:
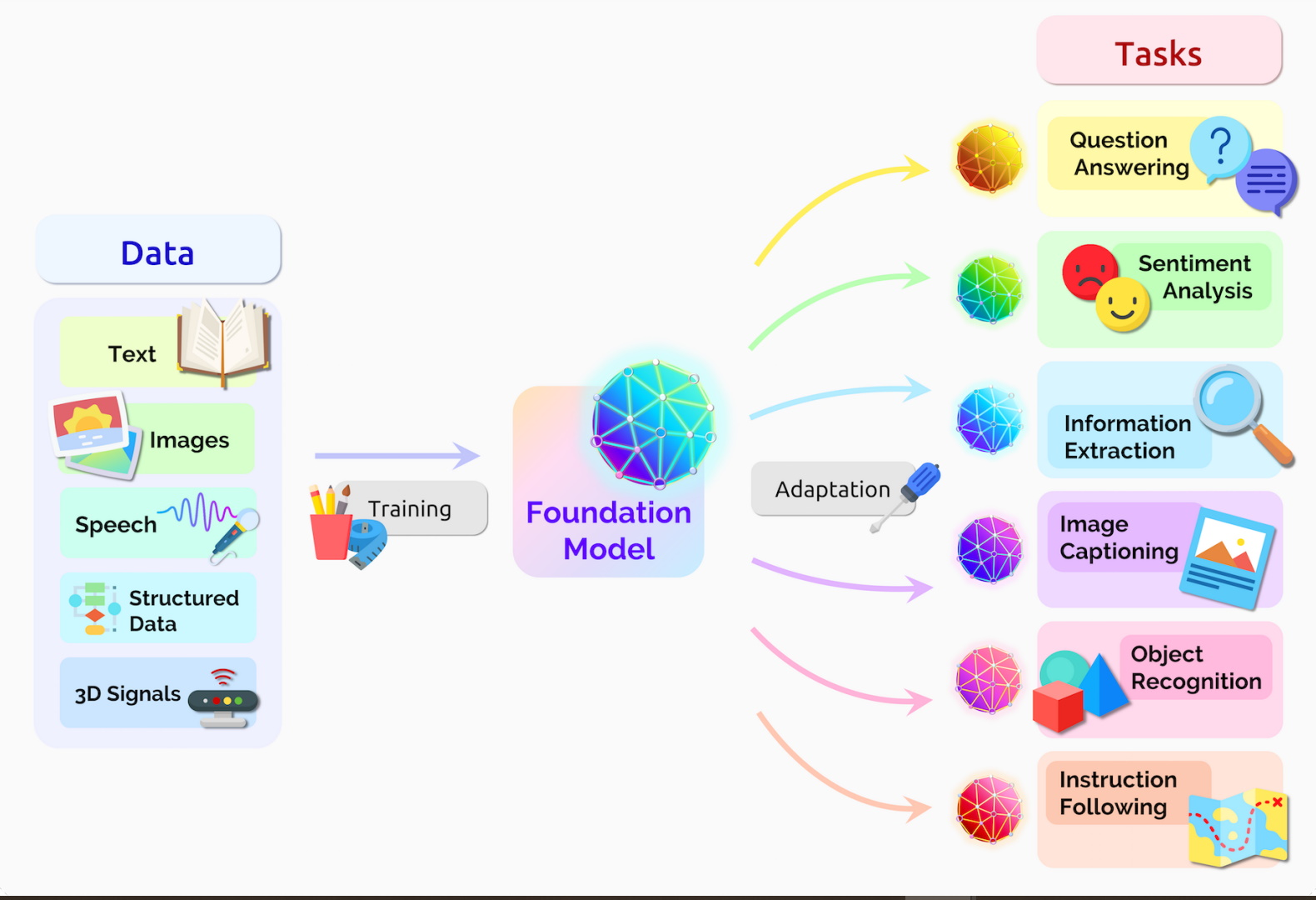
Data flow:

We define “Agent AI” as a class of interactive systems that can
perceive visual stimuli, language inputs, and other environmentally-grounded data,
and can produce meaningful embodied actions.
We explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback.
mitigate(감소) the hallucinations(환각) of large foundation models and their tendency to generate environmentally incorrect outputs
We envision a future where people can easily create any
virtual reality or simulated scene and interact with agents embodied within the virtual environment. (like the OASIS game in the film “Ready Player One” 영화 ‘레디 플레이어 원’의 오아시스 게임처럼 )
1. Introduction
1.1 Motivation
The AI community is on the cusp of a significant paradigm shift, transitioning from
creating AI models for passive, structured tasks to models capable of assuming dynamic, agentic roles in diverse and complex environments.
- 고도 구조화 고정 임무task 의 AI 모델 → 다양하고 복잡한 환경에서 역동적이고 Agent. LLMs and VLMs → a blend of linguistic proficiency, visual cognition, contextual memory, intuitive reasoning, and adaptability. 언어 능력, 시각 인지, 문맥 기억, 직관적 추론 및 적응력. → gaming, robotics, and healthcare domains. 게임, 로봇 공학 및 의료 영역 → redefine human experiences and elevate the operational standard. 인간의 경험을 재정립하고 업무 운용 수준을 높임. → transformative impacts on industries and socio-economic 산업과 사회경제에 대한 혁신 영향
1.2 Background
Large Foundation Models: can potentially tackle complex tasks
mathematical reasoning, professional law, generate complex plans for robots and game AI
수학 문제, 법학 문제, 계획 세우기 등등….
Embodied AI: leverages LLMs to perform task planning for robot
generate Python code → execute these code in low-level controller

Interactive Learning:
- Feedback-based learning The AI adapts its responses based on direct user feedback.

- Observational Learning: The AI observes user interactions and learns implicitly.
2. Agent AI Integration
Previous technology and future challenge
2.1 [Previous technology] Infinite AI agent
AI agent systems’ abilities:
- Predictive Modeling
- Decision Making
- Handling Ambiguity
- Continuous Improvement [Infinite AI agent] 2D/3D embodied generation and editing interaction
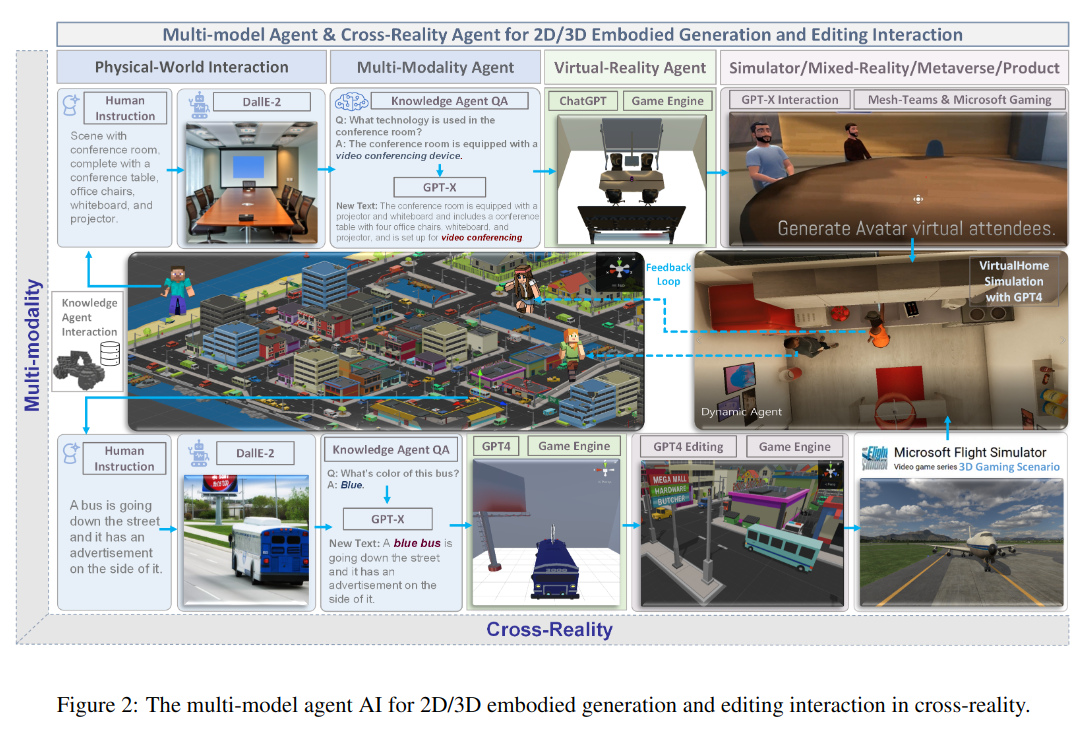 RoboGen: autonomously runs the cycles of task proposition, environment generation, and skill learning.
RoboGen: autonomously runs the cycles of task proposition, environment generation, and skill learning. ](/images/agnet_ai/Untitled%208.png) https://robogen-ai.github.io/videos/pipeline_cropped.mp4
https://robogen-ai.github.io/videos/pipeline_cropped.mp4
2.2 [Challenge] Agent AI with Large Foundation Models
2.2.1 Hallucinations(Fake answer)(환각)
2.2.2 Biases and Inclusivity(편견과 포용성)
Training Data / Historical and Cultural Biases / Language and Context Limitations / Policies and Guidelines / Overgeneralization / Constant Monitoring and Updating / Amplification of Dominant Views / Ethical and Inclusive Design / User Guidelines
학습 데이터 / 역사 및 문화적 편견 / 언어 및 문맥의 한계 / 정책 및 가이드라인 / 지나친 일반화 / 지속적인 모니터링 및 업데이트 / 지배적인 견해의 확대 / 윤리적 및 포용적 디자인 / 사용자 가이드라인
Mitigate(해결법):
Diverse and Inclusive Training Data / Bias Detection and Correction / Ethical Guidelines and Policies / Diverse Representation / Bias Mitigation / Cultural Sensitivity / Accessibility / Language-based Inclusivity / Ethical and Respectful Interactions / User Feedback and Adaptation / Compliance with Inclusivity Guidelines
2.2.3 Data Privacy and Usage
Data Collection, Usage and Purpose / Storage and Security / Data Deletion and Retention / Data Portability and Privacy Policy / Anonymization
2.2.4 Interpretability and Explainability
Imitation Learning → Decoupling 모방 학습 → 디커플링
Decoupling → Generalization 디커플링 → 일반화
Generalization → Emergent Behavior 일반화 → 새로운 행위
2.2.5 Inference Augmentation
Data Enrichment / Algorithm Enhancement / Human-in-the-Loop (HITL) / Real-Time Feedback Integration / Cross-Domain Knowledge Transfer / Customization for Specific Use Cases / Ethical and Bias Considerations. / Continuous Learning and Adaptation
2.2.6 Regulation
To address unpredictable output(uncertainty) from the model.
→ Provide environmental information within the prompt
→ designing prompts to make LLM/VLMs include explanatory text
→ pre-execution verification and modification under human guidance
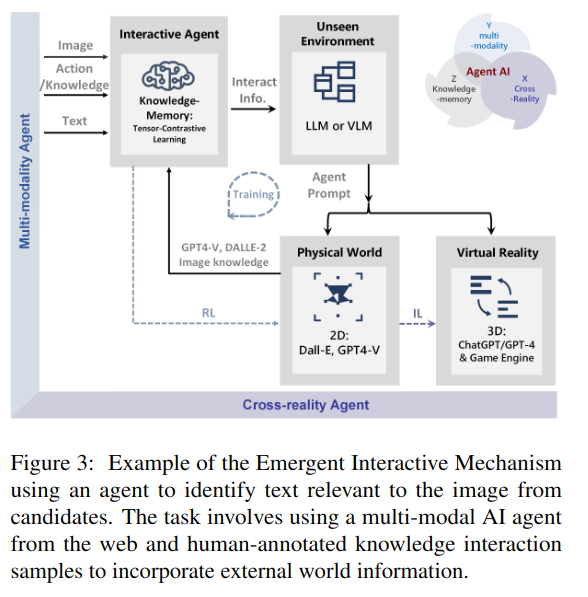
2.3 [Challenge] Agent AI for Emergent Abilities[새로운 능력]
Current modeling practices require developers to prepare large datasets for each domain to finetune/pretrain models; however, this process is costly and even impossible if the domain is new.
⭐Unseen environments or scenarios?
The new emergent mechanism — Mixed Reality with Knowledge Inference Interaction
Enables the exploration of unseen environments for adaptation to virtual reality.
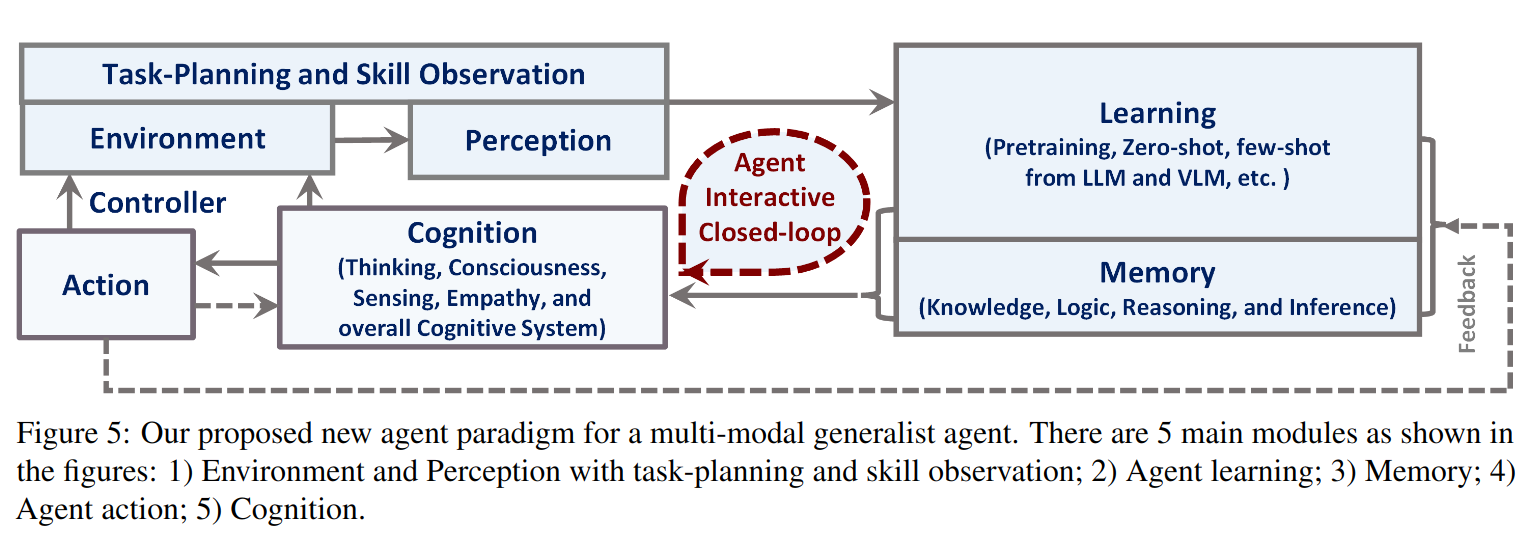
- Environment and Perception with task-planning and skill observation;
- Agent learning;
- Memory;
- Agent action;
- Cognition.
3 Agent AI Paradigm
We seek to accomplish several goals with our proposed framework:
- Make use of existing pre-trained models and pre-training strategies to effectively bootstrap our agents with an effective understanding of important modalities, such as text or visual inputs.
- Support for sufficient long-term task-planning capabilities.
- Incorporate a framework for memory that allows for learned knowledge to be encoded and retrieved later.
- Allow for environmental feedback to be used to effectively train the agent to learn which actions to take.
LLMs and VLMs|Agent Transformer Definition|Agent Transformer Creationc
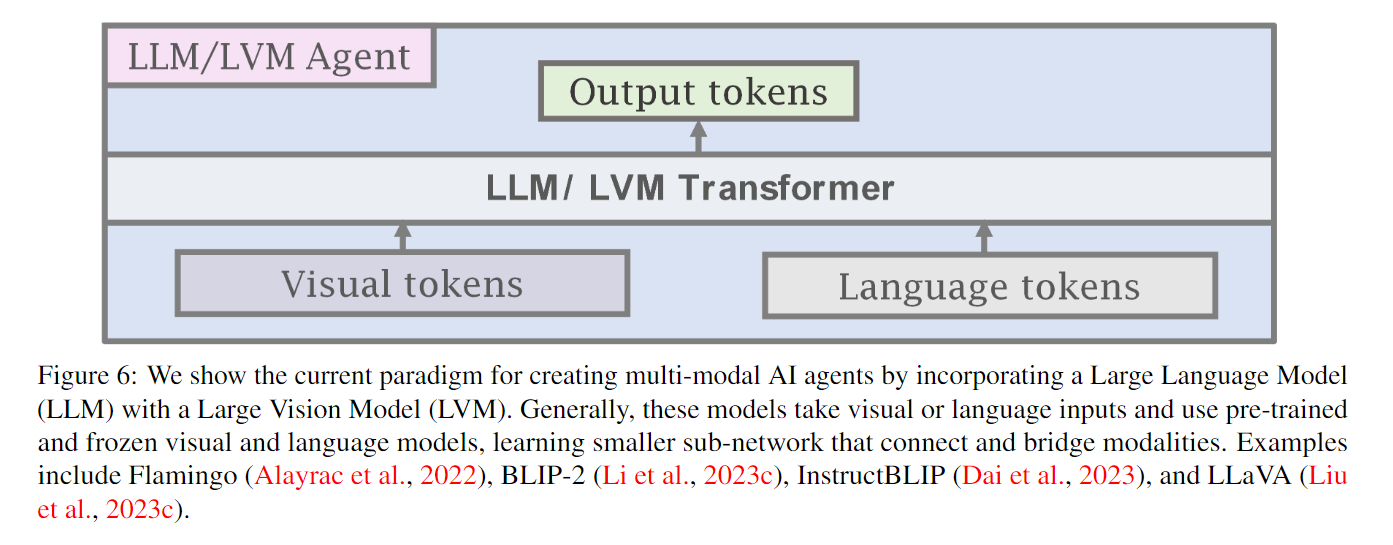
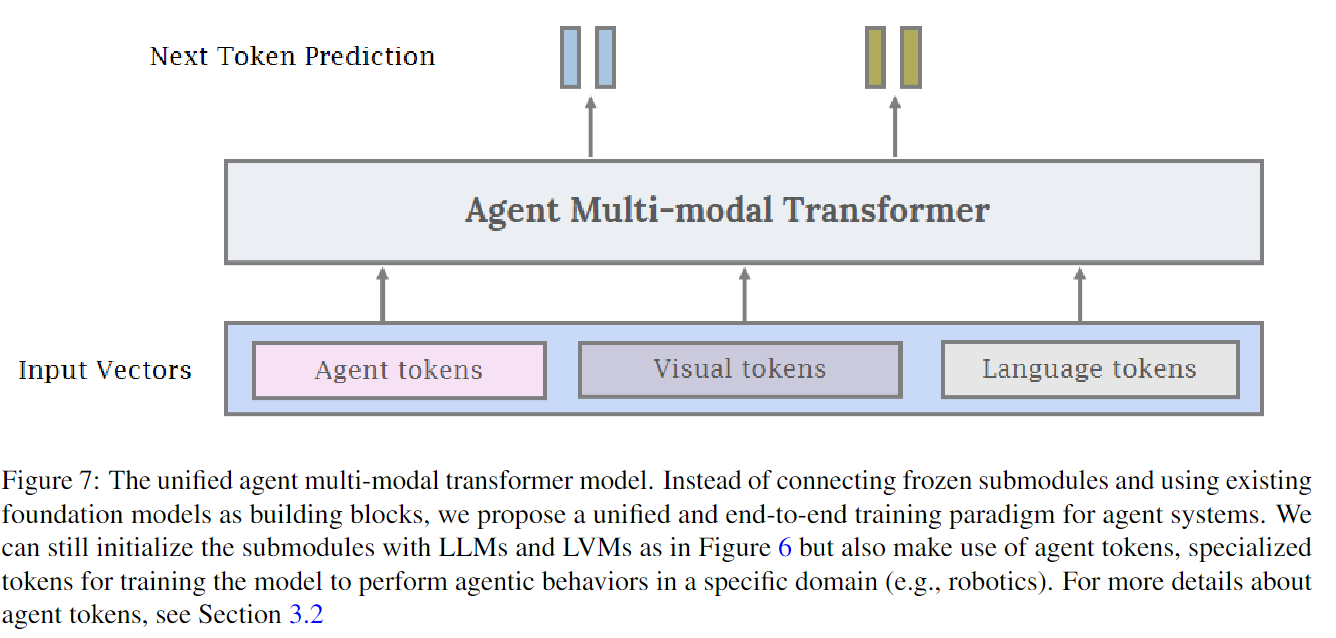
4 Agent AI Learning
4.1 Strategy and Mechanism
4.1.1 Reinforcement Learning (RL)
4.1.2 Imitation Learning (IL)
Seeks to leverage expert data to mimic the actions of experienced agents or experts
4.1.3 Traditional RGB
4.1.4 In-context Learning
4.1.5 Optimization in the Agent System
4.2 Agent Systems (zero-shot and few-shot level)
5 Agent AI Categorization
5.1 Generalist Agent Areas:
5.2 Embodied Agents
5.2.1 Action Agents
5.2.2 Interactive Agents
5.3 Simulation and Environments Agents
5.4 Generative Agents
5.4.1 AR/VR/mixed-reality Agents
5.5 Knowledge and Logical Inference Agents
5.5.1 Knowledge Agent
5.5.2 Logic Agents
5.5.3 Agents for Emotional Reasoning
5.5.4 Neuro-Symbolic Agents
6 Agent AI Application Tasks
6.1 Agents for Gaming
NPC Behavior
Human-NPC Interaction
Agent-based Analysis of Gaming
Scene Synthesis for Gaming
6.2 Robotics
Visual Motor Control
Language Conditioned Manipulation
Skill Optimization
6.3 Healthcare
Diagnostic Agents.
Knowledge Retrieval Agents.
Telemedicine and Remote Monitoring.
6.4 Multimodal Agents
6.4.1 Image-Language Understanding and Generation
6.4.2 Video and Language Understanding and Generation
6.6 Agent for NLP
6.6.1 LLM agent
6.6.2 General LLM agent
6.6.3 Instruction-following LLM agents
7 Agent AI Across Modalities, Domains, and Realities
7.1 Agents for Cross-modal Understanding(image, text, audio, video…)
7.2 Agents for Cross-domain Understanding
7.3 Interactive agent for cross-modality and cross-reality
7.4 Sim to Real Transfer
⭐8 Continuous and Self-improvement for Agent AI
8.1 Human-based Interaction Data
- Additional training data
- Human preference learning(사람의 선택 학습)
- Safety training (red-teaming)(보안)
8.2 Foundation Model Generated Data
- LLM Instruction-tuning
- Vision-language pairs
9 Agent Dataset and Leaderboard
9.1 “CuisineWorld” Dataset for Multi-agent Gaming
• We provide a dataset and related the benchmark, called Microsoft MindAgent and correspondingly release a dataset “CuisineWorld” to the research community.
Typo in 9.1.2 Task
9.2 Audio-Video-Language Pre-training Dataset
Video Text Retrieval
Video Assisted Informative Question Answering