YOLO-World: Real-Time Open-Vocabulary Object Detection
https://github.com/AILab-CVC/YOLO-World/blob/master/yolo_world/models/layers/yolo_bricks.py

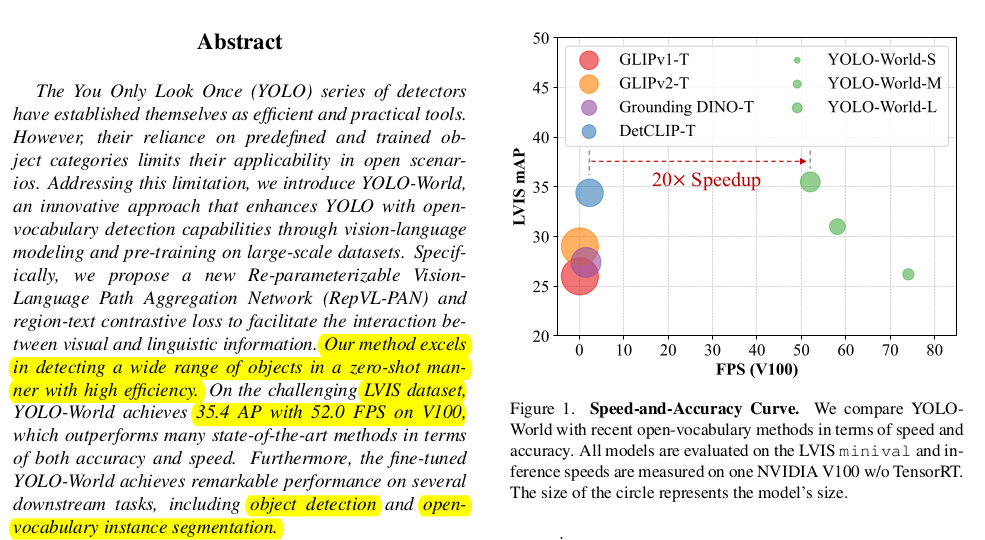
Open Vocabulary Object Detection
Open-vocabulary detection (OVOD) aims to generalize beyond the limited number of base classes labeled during the training phase. The goal is to detect novel classes defined by an unbounded (open) vocabulary at inference. [From link]
Novelty

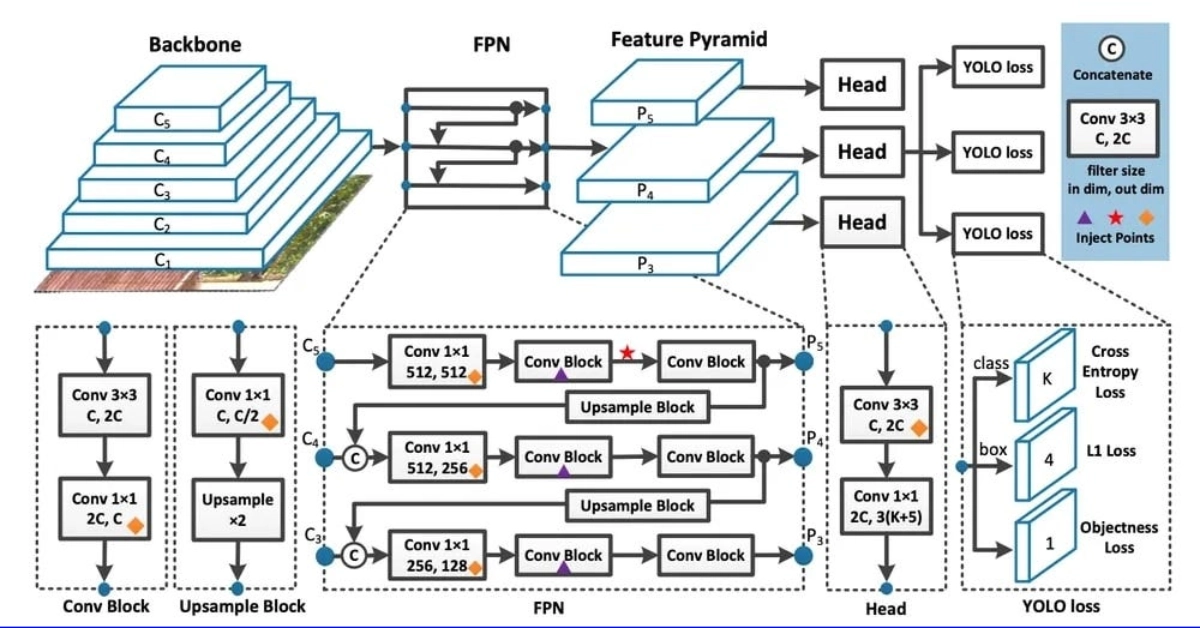
Traditional Object Detector
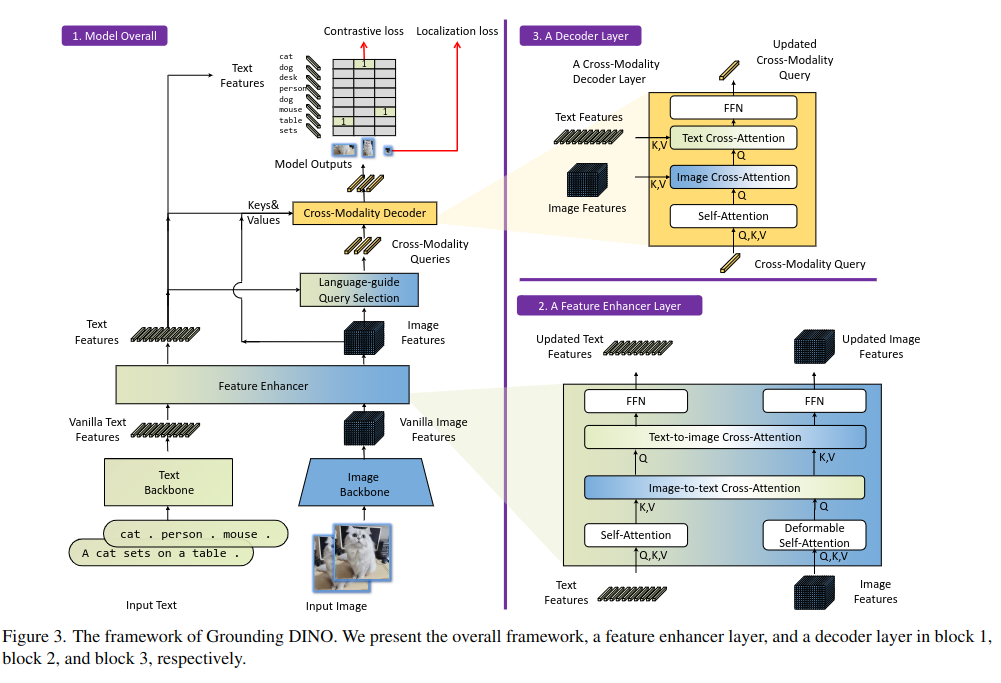
Previous Open-Vocabulary Detector
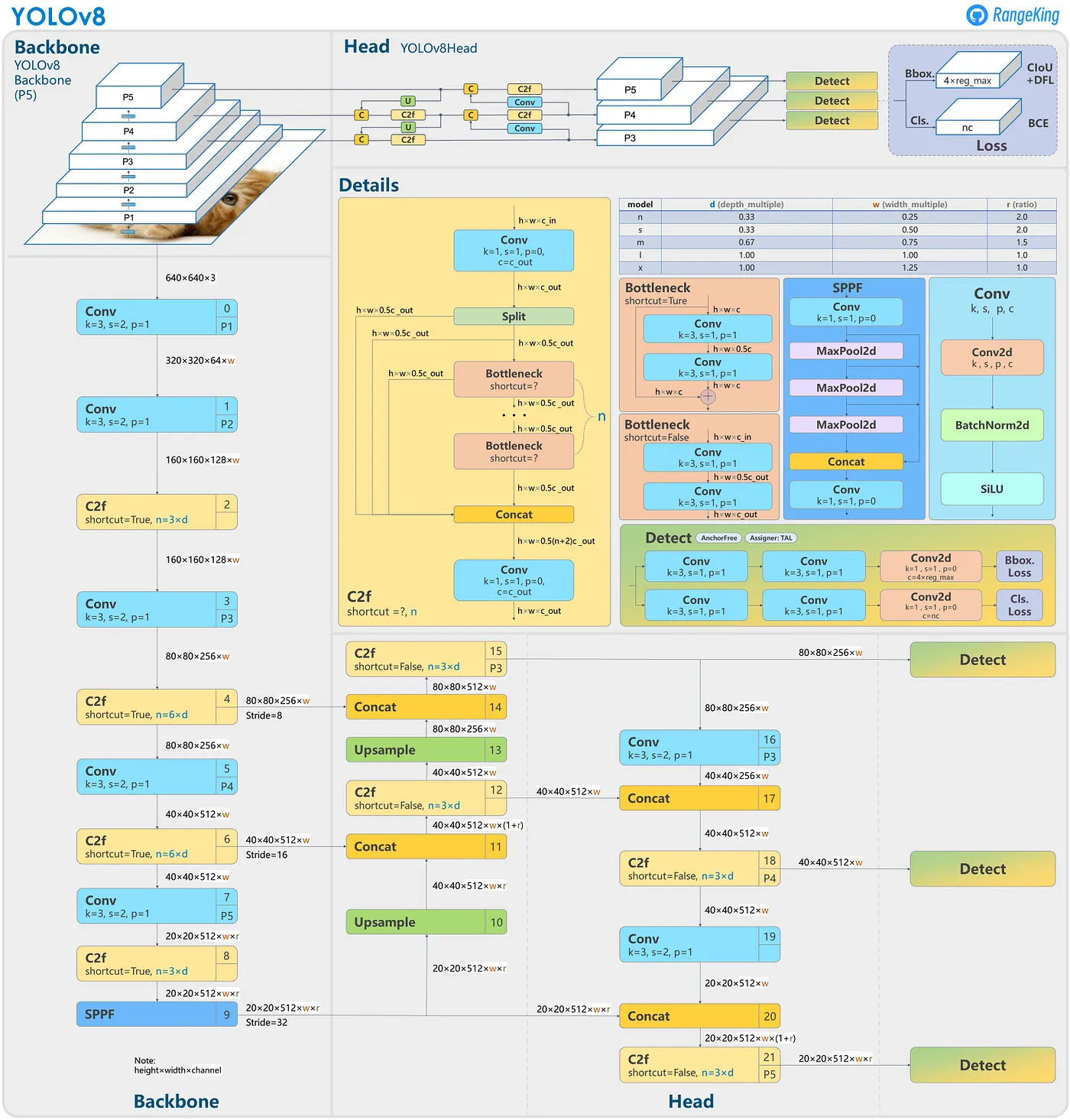
YOLO-World Model Architecture

Text Encoder(Clip)

YOLO Detector
YOLOv8 Backbone
Re-parameterizable Vision-Language Path Aggregation Network (Vision-Language PAN)
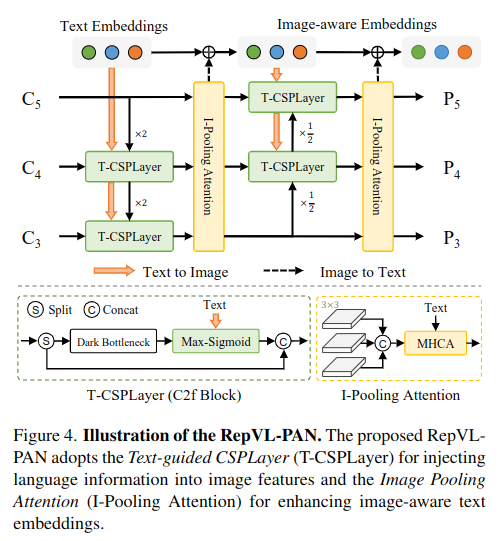
Text-guided CSPLayer(T-CSPLayer)
Dark Bottkneck(C2f Layer)

From: https://openmmlab.medium.com/dive-into-yolov8-how-does-this-state-of-the-art-model-work-10f18f74bab1
Max-Sigmoid
Image-Pooling Attention(I-Pooling Attention)
Text Contrastive Head
Region-Text Matching
Loss
is region-text contrastive loss
is IoU loss
is distributed focal loss
is an indicator factor and set to 1 when input image I is from detection or grounding data and set to 0 when it is from the image-text data.

