My rethink about Image generation and recognition
英文部分是Notion机器翻译
人类的大脑是图像生成最利害的机器,虽然我们无法直接向外表现出来,但是我们可以在大脑中想象出千奇百怪的东西,甚至在我们的梦境中,我们可以完全畅游在自由想像的世界。
The human brain is the most potent image generation machine. Although we can’t express it directly, we can imagine all sorts of things in our brains. Even in our dreams, we can fully roam the world of free imagination.
但是,我们人类是如何在脑中生成这些东西的呢?在我的理解中,纵使我们可以想象出任何东西,但是这个“任何东西”,很难超过我们的认知范围,即我们常说的想象的局限性。
But how do we humans generate these things in our minds? In my understanding, though we can imagine anything, this “anything” is hard to exceed our cognitive range, which is often referred to as the limitation of imagination.
我认为我们拥有这种局限性的原因是因为我们需要先观察已有的事物,然后抽象和思考这个事物的特征,才能想象出基于这个事物部分特征的其他事物。
I believe we have this limitation because we need to observe existing things first, then abstract and think about the features of this thing, in order to imagine other things based on some features of this thing.
因此,如果我们遵从人类的思考方式创建AI模型的话,我假设模型分为3部分: 观察,想象和思考。
Therefore, if we create AI models following human thinking, I assume the model is divided into three parts: observation, imagination, and thinking.
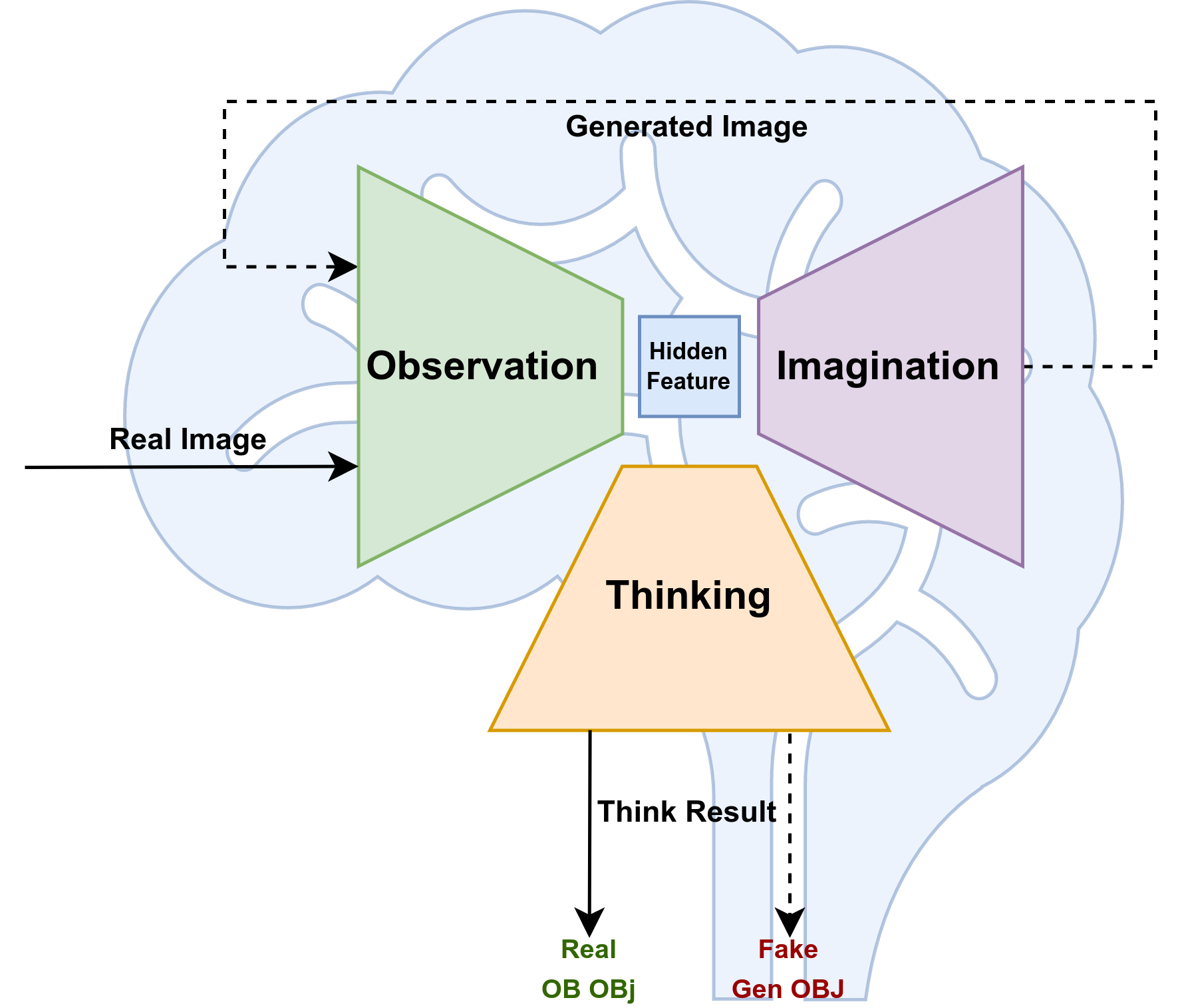
上图就是我认为的一个人类大脑的思维逻辑,或者说是一种图像生成的AI模型的结构,该结构有点类似于GAN(Generative Adversarial Network)模型。
The above figure is what I think is the logic of human brain thinking, or the structure of an image generation AI model, which is somewhat similar to the GAN (Generative Adversarial Network) model.
Observation: 我们将会观察真实图片,学习并提取真实图片的隐藏特征值(Hidden Feature)。
Observation: We will observe real images, learn and extract the hidden features of real images.
Hidden Feature: 观察到的特征值会被应用于两个方面,一方面是用于思考,一方面是用于生成图片。
Hidden Feature: The observed features will be applied in two ways, one for thinking and one for generating images.
Imagination: 我们通过总结到的Hidden Feature,可以试图生成一张新的图片,这张图片和原图Real image很相似,但是又不同,目的是为了生成一张能够让observation提取到和Real image相似特征的图片。
Imagination: We can try to generate a new image through the summarized Hidden Feature. This image is similar to the original Real image, but different. The purpose is to generate an image that allows the observation to extract features similar to the Real image.
让我们重新回到我们人类的思考学习方式上,当我们牙牙学语时候,假设我们认识“车”这个单词,老师会给我们一张车的图片卡,然后反复教我们这个东西是“车”。当我们记住了这张图片和与之对应的单词“车”之后,神奇的一幕发生了,即便我们看到了另一个模样的车之后,我们仍然能够“猜”出这是车!而这样神奇的能力我认为可以归因于人类想象力。因为人类在看到“车”的图片卡之后,我们不但是学习了车这个图片的特征,还学习到了很多抽象的特征,比如车有四个轮子,有方向盘等等,并基于这些抽象特征,天马行空的想象出了不同的车,而这些想象出来的车的样子,也有利于我们去识别真正现实中的车。在通过N次的对真实图片和想象图片的观察之后,我们便能思考“车”是什么,同是也具备了想象车的样子的模型。如下图:
Let’s return to our human thinking learning mode. When we were babbling, suppose we knew the word “car”, the teacher would give us a picture card of a car, and repeatedly teach us that this thing is a “car”. After we remembered this picture and the corresponding word “car”, a miraculous scene happened. Even if we saw another car, we could still “guess” it was a car! I attribute such magical ability to human imagination. Because after seeing the picture card of the “car”, we not only learned the features of the car picture, but also learned many abstract features, such as the car has four wheels, a steering wheel, etc., and based on these abstract features, the sky-horse-like imagination came out. Different cars, and the appearance of these imagined cars, are also conducive to our identification of real cars in reality. After observing the real image and the imagined image for N times, we can think about what a “car” is, and also have a model that imagines the appearance of a car. As below:
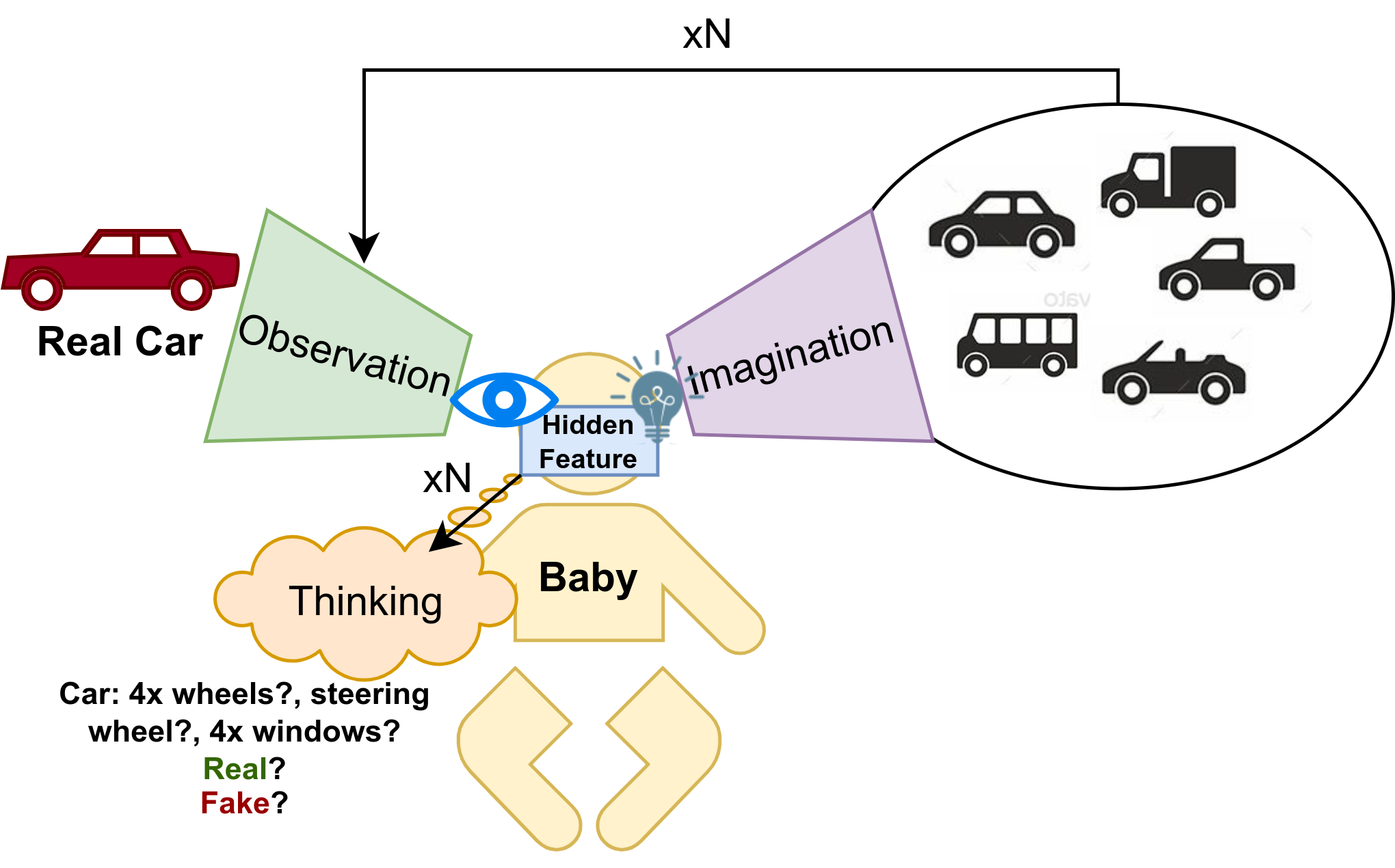
Thinking: 对于特征的思考,我们大致需要思考两个方面的问题:
图片是真的还是想象出来的?
一个真假二分类问题
图像描述的是什么?
一个NLP描述问题
Thinking: For thinking about features, we generally need to think about two aspects:
Is the picture real or imagined?
A true or false binary classification problem
What does the image describe?
An NLP description problem
因此,基于这一套思维逻辑,我们或许能够制作一个one-shot或者few-shot的模型,通过反复观测(Observation)和想象(Imagination)同一张图片并对他们进行思考,我们或许能生三个模型:encoder,generator,和thinker三个模型。如下图:
Therefore, based on this set of thinking logic, we may be able to make a one-shot or few-shot model, through repeated Observation and Imagination of the same picture and thinking about them, we may be able to generate three models: encoder, generator, and thinker. As below:
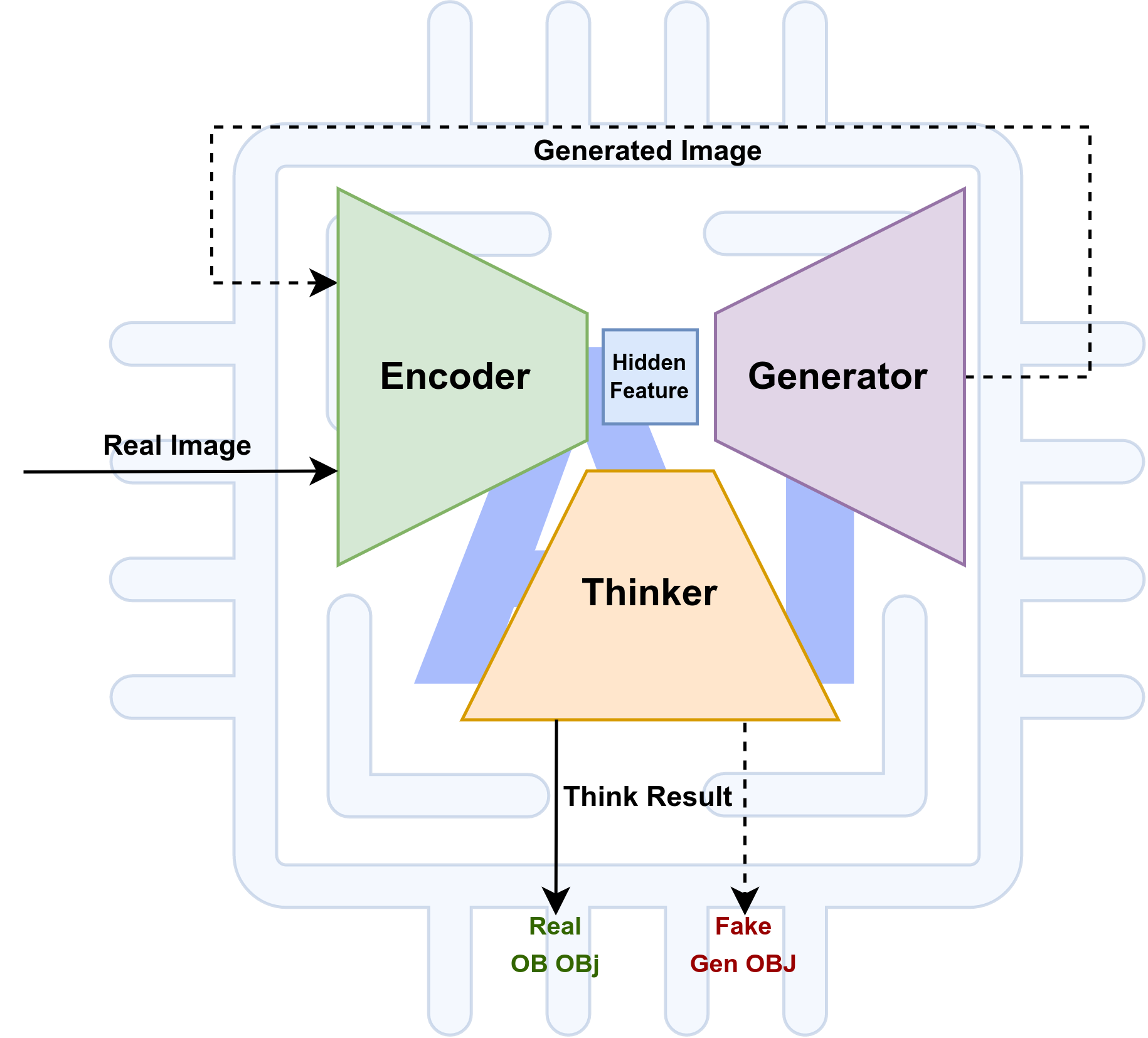
Loss 的设计,当我们设计loss函数的时候,主要是帧对在Thinker模块的输出,Real和Fake和对应的NLP描述均可以设计对应的距离loss函数。
When designing the Loss function, it is mainly designed for the output of the Thinker module, both Real and Fake and the corresponding NLP description can design the corresponding distance loss function.
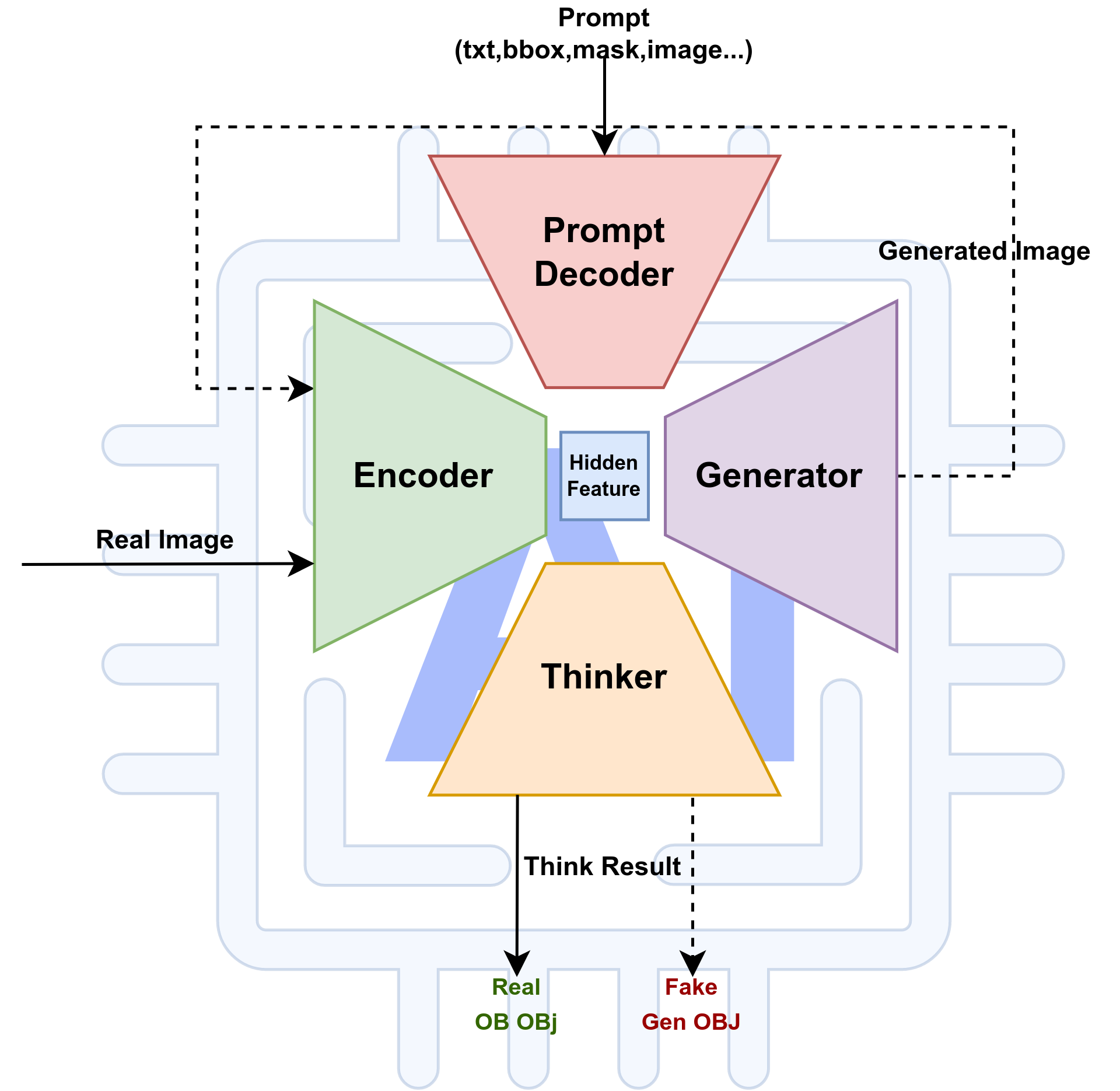
另外,我们还可以设计一个prompt编码模块,给我们的想象力加一点提示hint,从而更好的控制generator生成的内容。
Additionally, we can design a prompt encoding module to add a hint to our imagination, thereby better controlling the content generated by the generator.
以上便是我对于人类学习和AI学习的一点点思考。
The above is a little bit of my thinking about human learning and AI learning.

