AI version “Mining” system for AIGC: Take stable diffusion image generation model as a example
英文来自于Notion 机器翻译
介于现在AIGC模型的兴起,如果我们要生成一张图片,一些人在计算机算力上是非常缺失的,而另一些人却拥有非常多的计算机算力。此外,AI应用中,70%左右的算力都应用在了推演中。所以我在想,是否可以设计一个类似于以太币挖矿。我们可以用数字货币购买gas,而购买gas约等于购买算力和存储空间,然后我们便可以用gas部署我们的AI智能合约(Smart contract)。
With the rise of AIGC models, if we want to generate an image, some people are very lacking in computer computing power, while others have a lot of computer computing power. Moreover, in AI applications, about 70% of the computing power is applied in inference. So I’m wondering if we could design something similar to Ethereum mining. We can buy gas with cryptocurrency, and purchasing gas is approximately equivalent to buying computing power and storage space. Then we can use the gas to deploy our AI smart contracts.
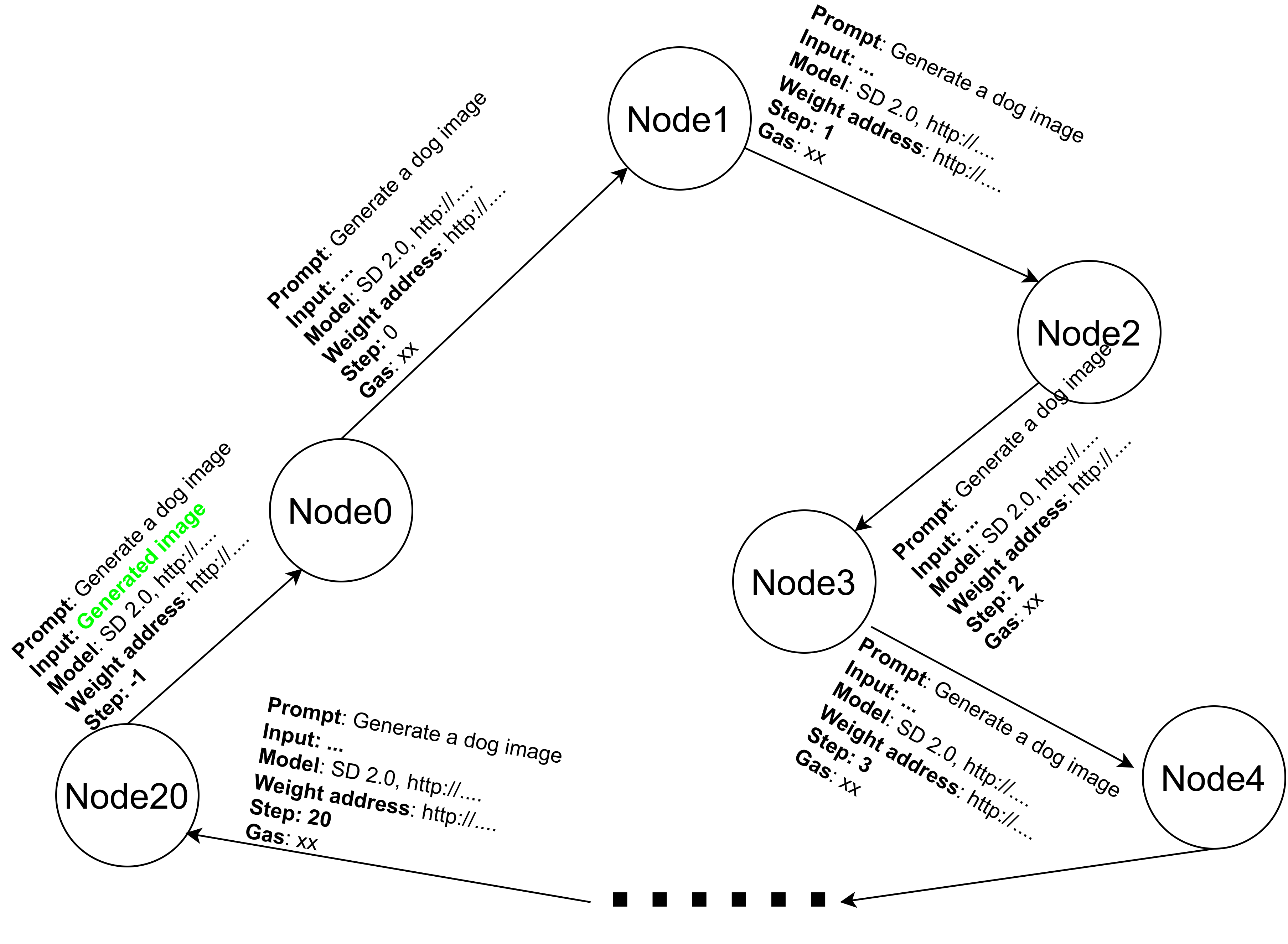
由于运行合约的时候,模型可能会被拆分到各台机器中运行,而可被拆分的模型是一个新兴的研究方向,如 Forward-Forward Algorithm和我的DFF: Distributed Forward-Forward Algorithm论文。目前研究的并不是很完善。因此,我们在这里将 stable diffusion model中的steps作为被分割的对象。即,我们将每一个step分割到各个机器中运行,如下图:
When running contracts, the model may be split into different machines for operation, and a model that can be split is a new research direction, such as the Forward-Forward Algorithm and my DFF: Distributed Forward-Forward Algorithm paper. The current research is not complete. Therefore, we will use the steps in the stable diffusion model as the split objects here. That is, we will split each step into different machines for operation, as shown in the figure below:
想在完成这套系统主要存在的问题有:(以后还会补充)
- 如何将通用的问题切割成小问题?
- 如果是要训练模型,训练的时候数据集又怎么处理?
- 每一个Node中如何评价是否“挖到”了我们希望得到的模型结果?
- 如何backpropagation?需要backpropagation吗?
- 如何解决并发的问题,如何将模型设计成并发推演或训练的?
The main problems that exist in completing this system are: (will be supplemented later)
- How to split general problems into smaller problems?
- If it is to train the model, how to handle the dataset during training?
- How to evaluate in each Node whether we have “mined” the model results we hope to get?
- How to backpropagate? Is backpropagation needed?
- How to solve concurrency issues, and how to design the model for concurrent inference or training?

