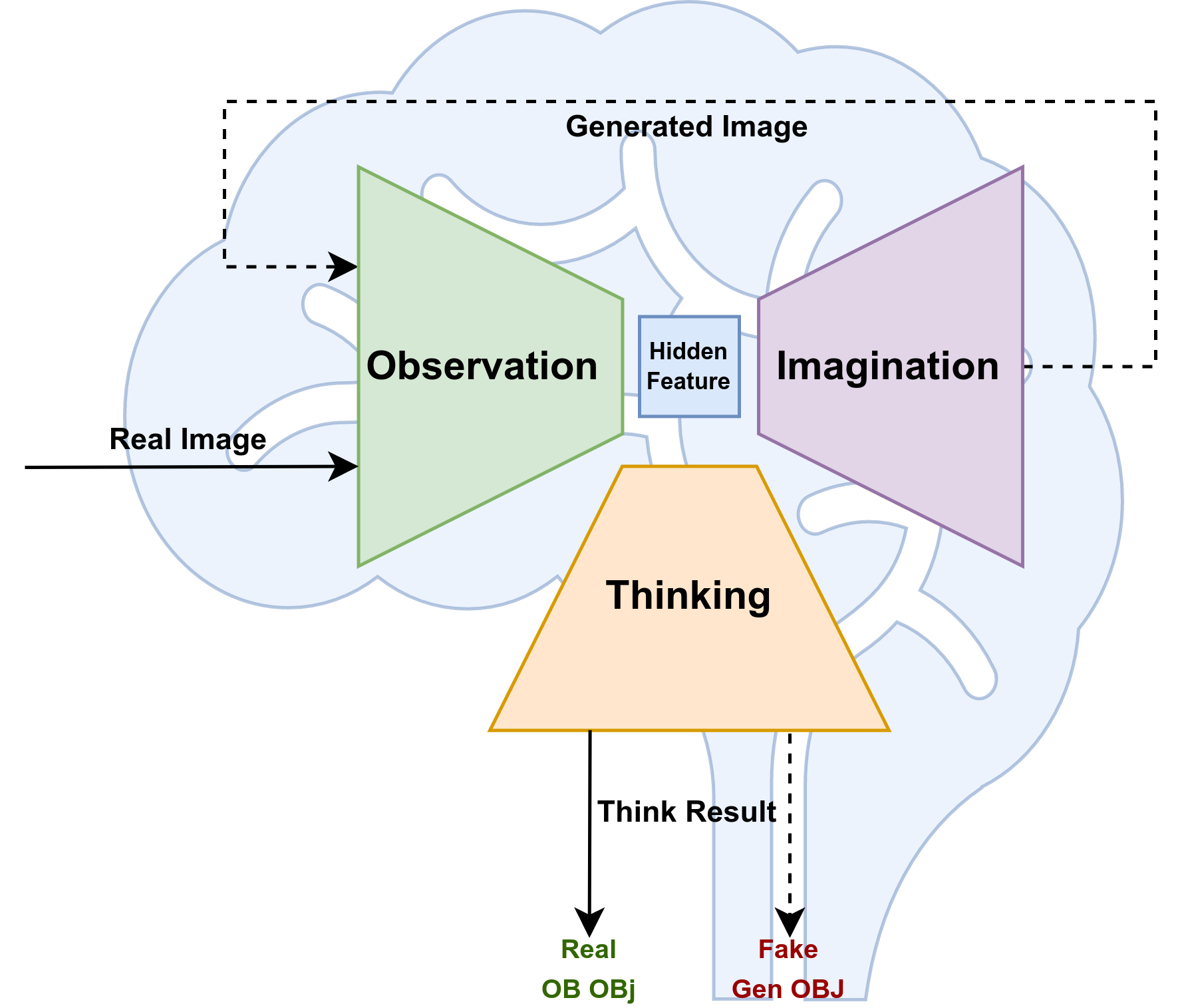
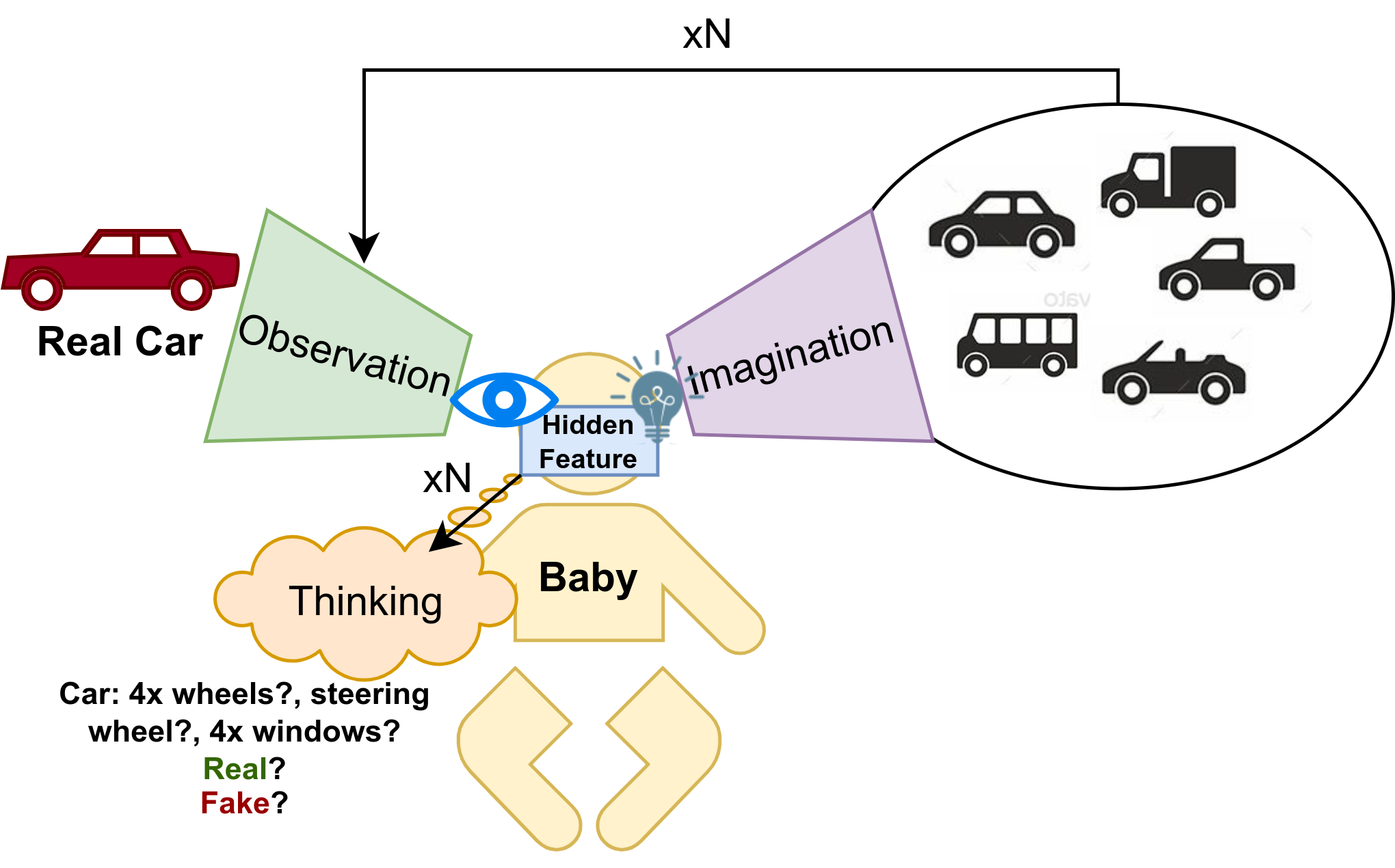
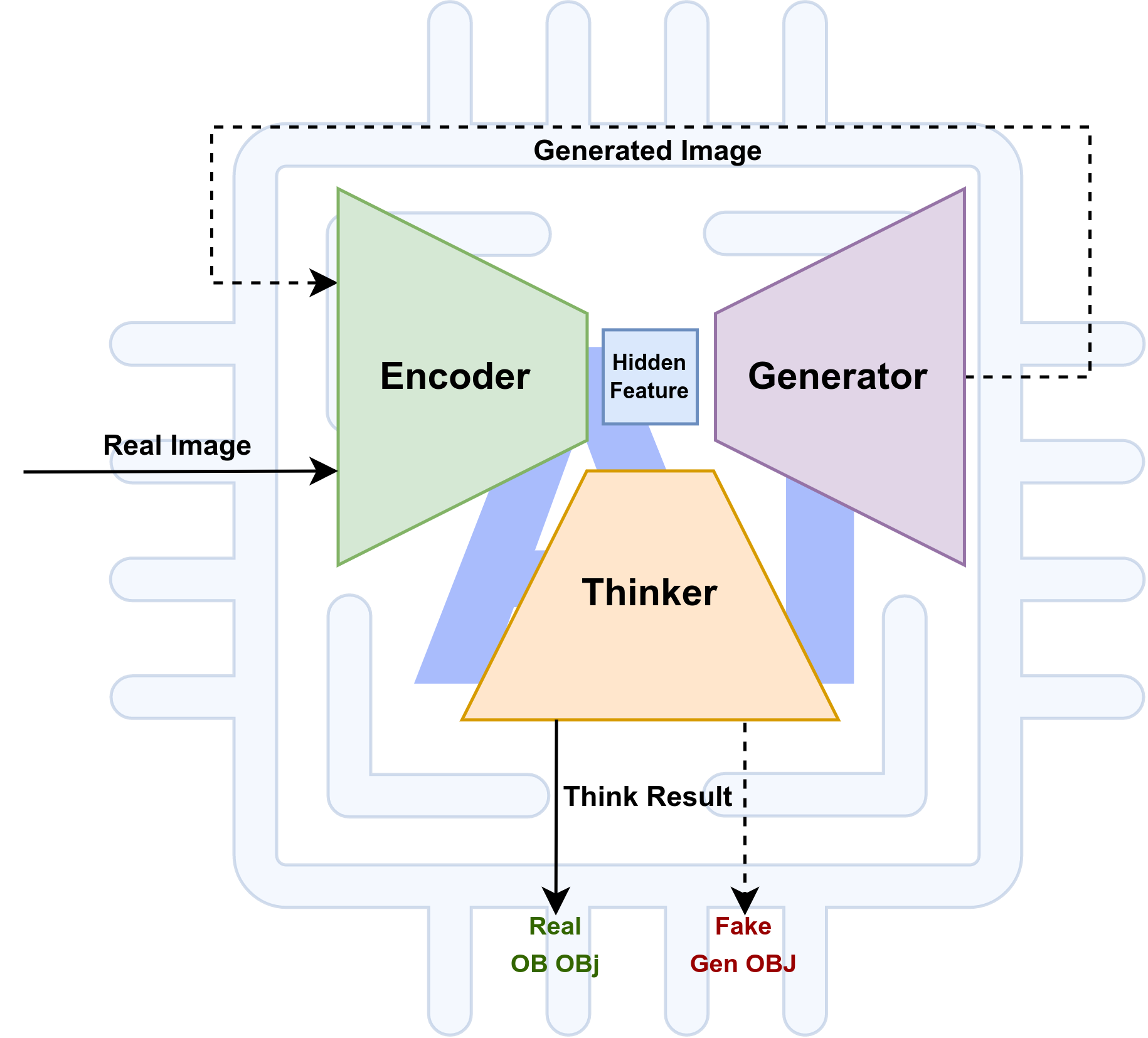
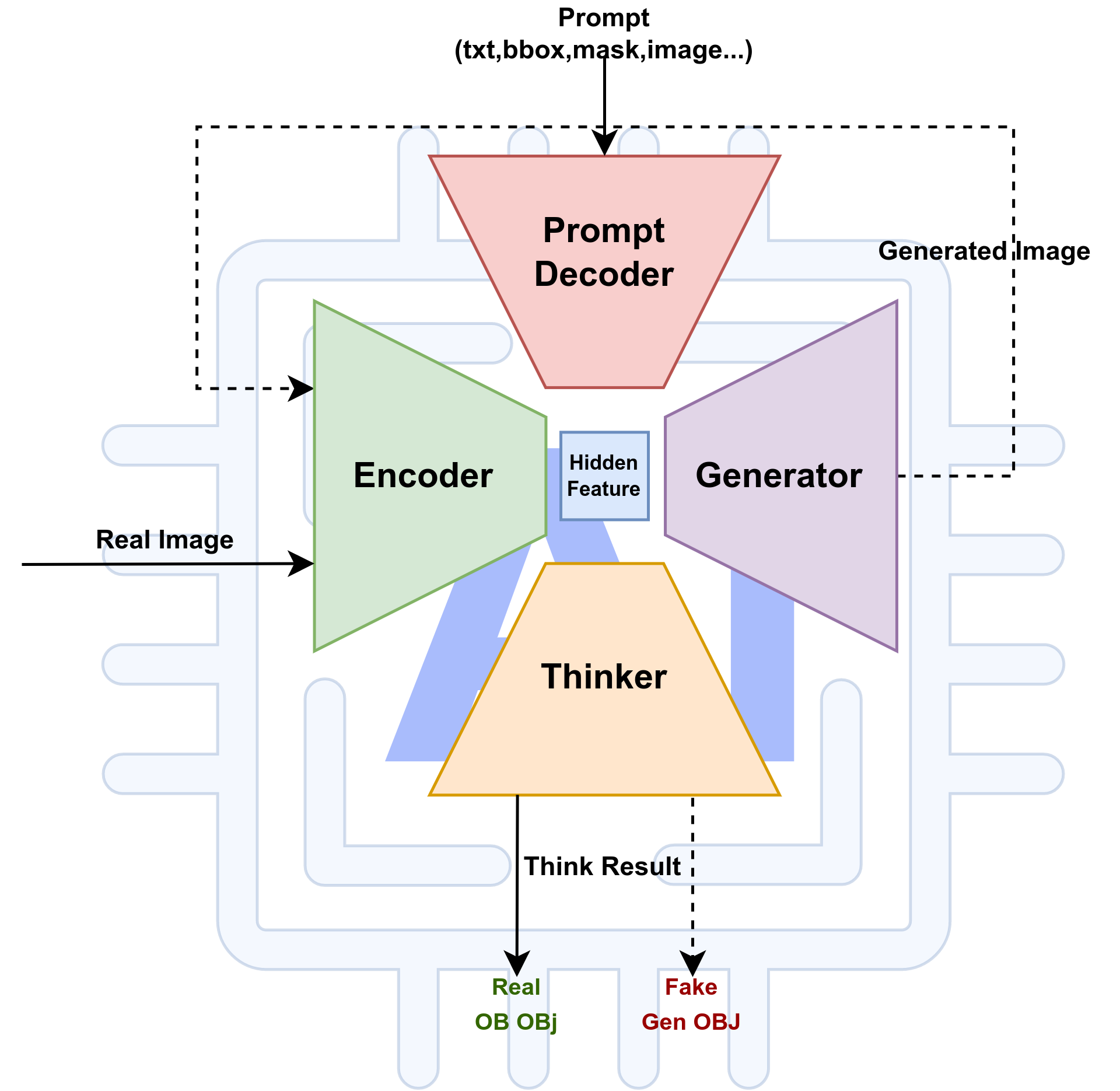
本人学习计算机已经快11年了,做人工智能的研究也有五年多了。研究生活当然不可能是轻松的,因为我们每天面对的都是突破人类知识极限的工作,不可能那么的顺风顺水。就算如何凯明这样的顶尖人物也曾经表示过:科研中95%的时间是令人沮丧的。我们其实就是为了那5%成功的喜悦而在一直的坚持着。但是,我们一生的时间是有限的,来自家庭,社会,前路的压力又是无限的。个人层面来说,如何在有限的时间内根据自身的实力,获得最大化的输入输出产出比将会是我们研究路上需要持续关注的问题。本人在这些问题上也是磕磕碰碰,跌跌撞撞很多年,下面是我这几年来,对于自己研究生活的一些心得体会。
1. 心态:
首先我想说的就是心态。在我的人生经历里面,心情和心态是最重要的一件事情。一个人,无论做什么事情,只有保持着愉悦的心情,乐观的心态,往往事情都会往好的方向进展。这次不行,下次再来,下次不行,那就换个方法,换个方式再尝试。毫无意外的成功当然是满心欢喜,但是接连不断的失败才是普通人的常态。
因此,每当我面临什么人生中的重要决策,重大事件的时候,我亲爱的爷爷(说到这,我突然非常的想念我的爷爷,我的爷爷于去年2024年4月的时候去世了,他离开之后没有闭上眼睛,我飞了2000公里的飞机回去亲手给我爷爷合上的眼睛,我想,他多少是有在等我回去吧。)。我亲爱的爷爷和我说的最多的就是那句引用自毛泽东的话: 战略上藐视敌人,战术上重视敌人。”战略上藐视敌人”意味着我们要敢于面对生活中的困难和敌人,要相信我们是有能力克服所有困难的。”战术上重视敌人”意味着我们在具体行动和计划上要非常认真谨慎,要做到没有任何差错。
总而言之,科学研究,心态很重要,不管身边的人多厉害,自己多着急毕业,一定要保持自己的心情愉悦。以一种平和的心态去认真的做自己的研究,水到渠成,自然而然,唯手熟尔。
2.最新研究信息获取:
说到具体的科学研究,我相信一开始大家都是迷茫的,不知道要做什么,做什么容易出结果,自己有善长做什么?说实话,我到现在都还搞不清。但是我想,大家都在做的应该都不差吧,站在巨人的肩膀上总该是最保险的吧。所以,除非你有一个非常坚定想做的东西,愿意为它付出终生的东西,不然就获取最新的研究信息然后跟着别人做吧。我知道肯定很多人会反驳我,说是科研是要有深度,有次序性才能有巨大成果。但是考虑到我们在做的是人工智能领域这个飞速发展的领域,已经有大把的资源和人力投入到了这个领域,我半年前看到文章现在来说都已经过时不再用的这种领域,真的不再渴求能多坚持研究了。加上我们都还是普通人,真的没办法和有资源,有人脉和大拿们比。
那到底要怎么获取最新的研究信息呢?
我认为可以大致分为三种渠道:
- 网络渠道:网络渠道是最好的了,不求人,信息量大,更新快。有大量的免费网站可以让我们每天看到最新的研究情报。 比如: https://deeplearn.org/ https://paperswithcode.com/ https://huggingface.co/models https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/ 这些网站都会贴出实时的最新论文和代码,我们可以根据自己的研究follow.
- 招聘市场: 招聘市场要什么人,这就意味着这个方向肯定是时下最热门和最有可能创造商业价值的方向。我们不一定在这个方向研究,但是这个方向基本的知识和技能时需要具备的,同时也时为了可以更好的支持自己做项目的能力。
- 人际交往: 别小看了人与人的力量。有句老话叫做“当局者迷,旁观者清”。当我们陷入到研究的困境之中的时候,我常常会看不到问题的重点在哪。尝试着与有相关经验的人交流,提问,或许能够摆脱我们的思维惯性,找到更好的方法。那如何认识这些有相关经验的人呢?我觉得就一句话:迈开腿,打开嘴,不害羞,勇敢问。多开学会,多加入交流学习组,不管时在网上还是现实世界中,都打开自己的社交圈,不要害羞,多问,多听,多学习,总能获取到正确的信息的。
3.个人研究:
在我们进行了大量而广泛的论文阅读之后,我们应该时大概知道自己可以尝试做的某个方向了。个人认为,与导师确定研究方向是非常有必要的,但是在你和他推荐你的研究方向的时候,请务必准备的足够充分和自信,最好是有一定的研究成果了。为什么呢?因为这样子导师才会有信心认为你可以坚持做下去这个方向的研究,或者即便做不下去了,以现在的研究成果也能有一些小的产出。
那具体怎么确定研究方向,做自己的研究,并获得成果能?我觉得有一下几个方面:
- 广泛查看高质量论文: 计算机和人工智能行业很特殊,是一个理论与工程实践都非常重要的学科,你甚至都无法做假,因为代码不会说谎。这意味着,我们在看到一篇很有价值的论文的时候,还得确认其代码,运行看看是否如论文描写的那样有用。当我们积累了某个方向的论文和代码知识之后,研究idea自然就会有了。
- 以他人的研究为基础产生研究idea: 虽然完全从无到有构建一个研究idea也是可能的,但是这样的idea需要我们有结实的数学基础证明其理论可行性,有极度熟练的变成能力将理论变成工程学上可用的代码,还需要有一点运气(成功的运气和在你完成之前其他人没有出版的运气)。
- 切勿追求极致的完美: 我相信,科研人一开始都想将东西做到完美,完美之后才考虑发表。但是阿,人生能有几次完美。如果我们的结果达到可以投稿水平了,我建议是可以先投稿一篇论文,然后继续研究cycle,将这个问题做得更完美。
- 要有一个研究cycle的计划: 完成一篇论文之后,就得安排好进入下一个研究cycle(发现问题→查阅论文→找出可以改进的点→实验→结果→论文)。
4.身体健康和研究时间规划:
在面对高压的科研环境和项目压力的时候,我们难免会面临很多健康问题。这个时候强健的体魄就尤为重要了。这一方面我并不是一个正面的例子。在最忙的时候没有办法,还是会通宵的跑实验和写论文。但是,身体健康是持续研究的一个重要的保障。为了有一个良好的身体状态和心情去坚持研究工作,合理的时间规划就显得尤为重要了。
- 首先,schdule做出来,就要坚持,要做自己能完成的schdule。
- 其次,每一个任务要有一定的富余时间,不能卡deadline,否则的话如果有什么意外事件发生耽误时间了的话,你就会特别的急,特别焦虑的去做接下来的事了(势必也会熬夜)。
- 要分清任务的轻重缓急,我知道这句话大家都知道,但是真的很重要,比较轻且不急的事情我们可以放下慢慢做,被耽搁了也无所谓。其实还有一类事情,就算预估会失败的事情,对这种事情,我们也需要懂得取舍,该放弃就放弃吧,现在的放弃是为了以后更好的结果。
- 最后就是,如果真的遇到了紧急情况,熬夜是不可避免的,熬夜不要超过两天,可以选择在白天睡四个小时左右补充体力。
- 人生苦短,即使行乐,该玩的时候好好玩,该认真工作的时候好好工作。
5.论文写作:
我们有了一定的研究成果之后,就得写论文了。论文除了有一个好的实验结果之外,也可以是一个好的idea或者是个好的故事。
写好一个故事是写论文的一个重要的技巧,没有任何一个reviwer会花时间去弄清楚你的所有细节。你呈现给他们什么,他们就会看什么。你的写作有趣,有意义,才会吸引reviwer去看。如何写好一篇论文的故事呢?
- 写作能力: 这个没有任何人能帮助你,连chatGPT也没办法帮助我们的。这不是简单的单词语法的问题(当然单词语法也很重要,即便是有GPT帮忙了,我们仍然要小心),是语言习惯和结构习惯的问题,只有通过大量的阅读来提高。
- 构建故事之-Motivation: 一个好的Motivation就是一个好的开头,motivation有趣或者解决实际问题的话,就会非常吸引人们继续看你的论文。除非你是最顶尖的研究员,不然的话请遵守这样的规则。
- 构建故事之-Contribution:
好的故事当然得有好的方法和贡献才能体现文章的价值。或许我们有些时候很难作出突破性的贡献,这让我们很沮丧,但是我们可以从不同的出发点证明我们方法的贡献,比如:参数量,新颖有效的算法设计,计算时间,内存使用量,效率,多任务等等。同时,我们可以适当的描写我们这些贡献可以为哪些应用,哪些后续任务提供宝贵经验,这样子来体现论文的价值。 - 构建故事之-Result and Conclusion: 结果和结论的描述非常重要,审稿人通常非常关心这一部分的描述,因此,请慎重的选择需要呈现的结果,不要只是随意的把SOTA结果放上去比较。本论文的结果需要和与本论文类似的条件下的模型的结果进行比较,从而体现本论文方法的优越性。如果可能,也尽量做一些ablation study来进一步证明论文种使用的方法能够提高性能。
- 多使用简洁,简单的句子,少用复杂长句子: 作为东亚地区的人,书写英文的时候容易出现一个思维惯式,认为复杂的长句子才能体现我们写作的专业性。从论文写作上来说,有这样的写作能力的话,长句子当然能体现我们写作的实力和专业性。但是,东亚地区的人语言习惯上容易把主语混用,导致一个句子中表达的主语有很多个,这会导致阅读困难。因此,我认为,在我们写作能力有限的情况下,简单的,多个的句子方而更能解释说明我们想要表达的内容。
- 图表一定要严谨 审查员第一次看论文的时候,第一眼看到就是,abstract, figure, table, result 和 conclusion. 这意味这我们的图表需要极致的完美,因为图表的缺陷非常容易被察觉出来。图表中任何错误都容易被放大。最容易出现的错误就图表的caption, 图表内文字错误等等。
- 活用工具 在撰写论文时,熟练运用各种工具可以显著提升写作效率,例如使用LaTeX排版论文和制作图表、DeepL辅助翻译、Grammarly检查语法、ChatGPT帮助构建框架和逻辑、Notion AI优化文本表达,Diagram绘制图表,以及google scholar构建reference样式等。
6.论文投稿:
论文完成后,就让我们投稿吧,常有这么一句话:选择大于努力。选择一个好的期刊可以让我们的论文获得更高的性价比。先来介绍一下计算机领域国际期刊和学会的分类。
期刊:
Journal Impact Factor(IF): 通常,SCI论文IF越高期刊水平越高

索引: SCI/SCIE, EI/EI Compendex, Scopus, ACM Digital Library/IEEE Xplore等
JCR journal ranking(SCI索引):
1区 顶尖期刊,排名前25%
2区 中高水平期刊,排名25%-50%
3区 中等水平期刊,排名50%-75%
4区 相对一般,排名75%-100%出版商:
IEEE/ACM/Springer Nature/Elsevier/Wiley/Oxford/MDPI/Hindawi/Frontiers
通常来说, JCR 1区; 出版商:IEEE, ACM, Nature/Elsevier; CFF A区最佳。实力按照介绍顺序递减。
学术会议Conference:
Conference的情况比较复杂,每年都会有比较大的变化,韩国有BKlist, 中国有CCF list,可做参考。通常 国家<地区<国际,举办次数越多的,起码证明他有稳定的投稿支持它一直开下去。
相比于journal, Conference能够快速接触到最尖端的最新的技术和最利害的人。我认为多参加conference对于个人的研究还是非常有利的。不要嫌累或需要花钱,这是我们能够最直接了解专业动向,认识志同道合之人的地方。学会上了解到的知识和认识的人或许会成为我们下一篇论文的一部分。
7.论文合作:
我认为,要是有和实验室之外其他人合作的机会的话,那将会是一个非常不错的经历。这样的合作能够让我们从不同的视角查看我们的研究的合理性。学术研究不是蒙头造车,只有多交流,多合作才能发现主要的问题和想出有趣的方法。
论文合作主要有两种类型:
同专业合作:我没有这方面的经验,但是要是有这种机会的话,建议多参与。目前优秀的论文大多都不是一个机构写出来的,经常是几个机构一起合作完成。
交叉学科合作:
由于计算机,特别是AI的特殊性,我们寻求交叉学科的合作其实是非常有优势的,而且可能任务也不难,但是这样的交叉学科合作的经历能够丰富我们个人简历,显得更据有实力,甚至之后以计算机专业为基础转成其他专业的研究也是可能的。
8.项目经验:
项目经验不仅是对所学知识的综合运用,更是将理论转化为实际解决方案的关键途径。在科研之外,系统地参与高质量项目能够显著提升我们的综合竞争力,体现我们在真实问题场景中的思考能力与执行力。在用人单位眼中,是否具备将理论知识落地为实际方案的能力同样重要。项目经验正是这种“可落地能力”的集中体现。一个完整的项目往往包含需求分析、方案设计、模型实现、效果评估和部署优化等多个环节,能全面展示我们的技术广度、工程能力和协作能力。
培养实际解决问题的能力
通过项目实践,我们不仅熟悉了各种工具链与工程环境,更重要的是学会了如何在复杂、真实的系统中定位问题、拆解问题,并找到最优或次优解。这种能力远远超越了纸面上的知识,它代表着一种系统性思维方式与强执行力,真正做到“解决问题”而不是“做研究”。
求职的时候
在求职过程中,项目经验往往比论文更直观、更具说服力。用人单位更容易从项目经历中看到我们是否具备岗位所需的技能、是否能快速适应工作环境。例如,在简历或面试中,我们可以通过“问题背景-解决方案-实现方式-结果分析”来结构化介绍项目,让面试官快速理解我们的能力亮点。此外,许多岗位也更看重项目中的实际产出,如代码质量、性能指标、用户反馈等,这些都是论文中难以体现的。
9.资源限制:
资源是有限的,人类的欲望是无限的。我们在做研究的时候势必会遇到资源有限的问题。
物理资源有限(算力、设备、时间……):
优化模型结构、使用轻量级方法
用更巧的方法
利用开源工具
把问题拆成多个小问题,一个一个小问题来解决,解决一个小问题出一篇论文
先解决“最有性价比的问题”。
人脉资源有限:
积极参与线上社区、技术论坛、开源项目、学术会议
小规模合作也可能激发新的灵感
一个好项目、一篇好文章、一次分享,都是你“资源积累”的过程,个人人气的积累
试图 高效沟通、深度协作
10.挫折管理:
知道自己的实力,量力而行
最后但我们作出了所有的努力之后,可能结果还是不会如我们期望的那样。我们应该提前做好有不好结果的打算。我们要了解自己,了解自己的极限。人一辈子都在认识自己,理解自己,从而突破自己的极限,所以,人生路上,这些挫折和失败都是不可避免,可以接受的,我们失败了,振作起来在试一试。事不过三,三次都不行,我们就放弃,找找其他办法吧,条条大陆通罗马。

 |
| 





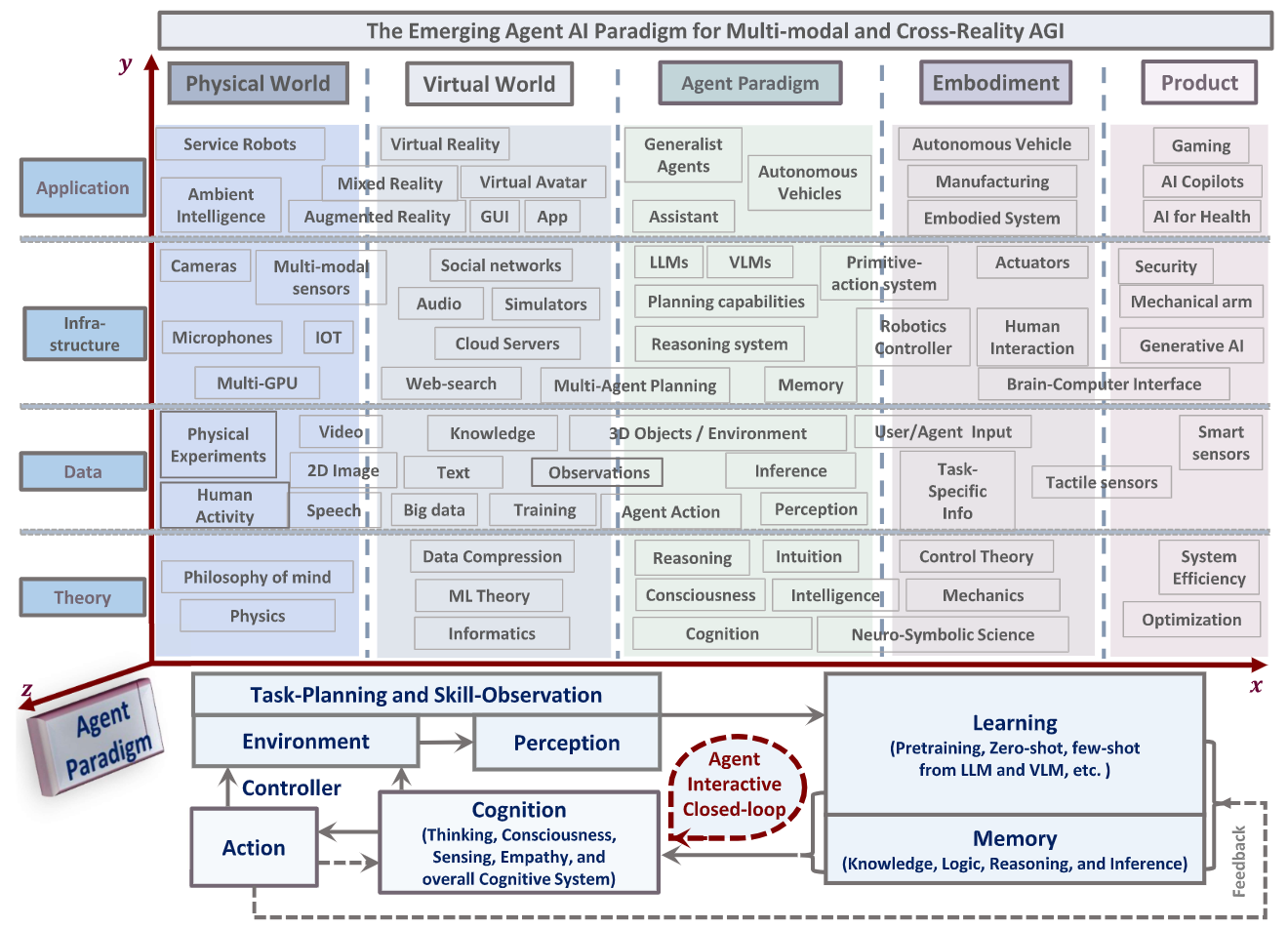

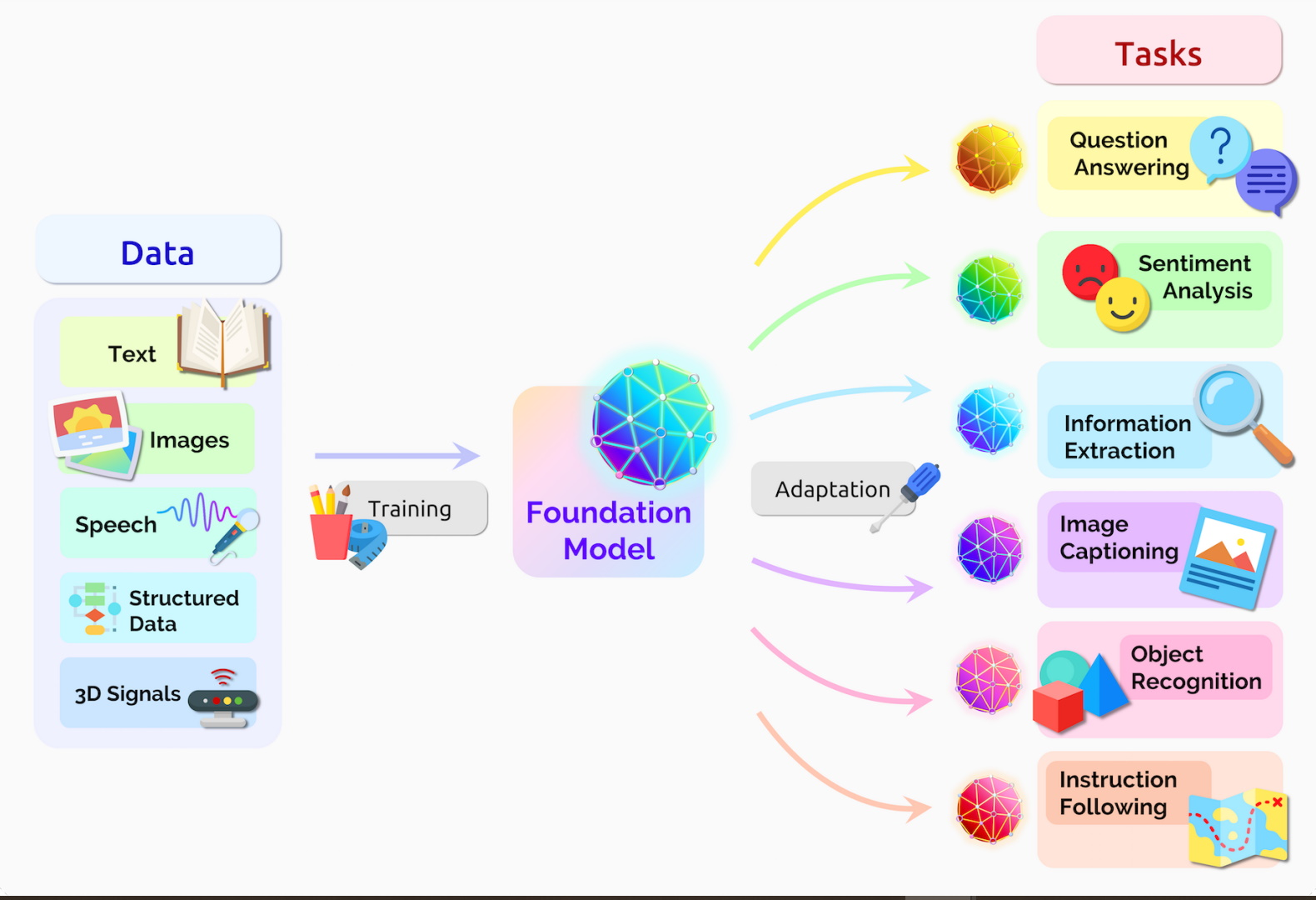


 RoboGen: autonomously runs the cycles of task proposition, environment generation, and skill learning.
RoboGen: autonomously runs the cycles of task proposition, environment generation, and skill learning. ](/images/agnet_ai/Untitled%208.png)